Introduction

E2E Cloud has emerged as one of the top 3 Infrastructure as a Service (IaaS) providers globally in the recent G2 rankings, ranking ahead of other popular cloud providers like Azure, Digital Ocean, to name a few. The platform received excellent ratings from users across various industry domains.

Infrastructure as a Service (IaaS) is a cloud computing model that provides on-demand access to highly scalable computing resources, including cloud GPUs, compute resources, storage, networking, DBaaS, which helps startups and enterprises build applications without the capital expenditure that comes with buying hardware. This field has long been dominated by major global players. However, E2E Cloud, the India-born NSE-listed hyperscaler, offers more performant cloud infrastructure than others. This is what has led to E2E Cloud emerging as one of the fastest growing and amongst the top 3 globally.
Over the years, E2E Cloud has become the platform of choice for startups that want to scale. The company boasts over 15,000 customers served, with more than 2,600 active customers. Prominent startups like CarDekho, universities like IIT Madras, and partners like FluidStack, all leverage E2E Cloud’s highly performant cloud infrastructure.
Founded in 2009 by Tarun Dua, E2E Networks embarked on its mission to provide businesses with robust computing resources and a suite of cloud technologies at competitive prices.
E2E Networks went public with an initial public offering (IPO) on the NSE Emerge platform in May 2018, receiving an enthusiastic response that saw subscriptions reach 70 times the offered amount. Following its success, the company transitioned to the main board of the NSE in 2022.
What Differentiates E2E Cloud from Its Competitors
1. Top Price-Performance Ratio
Below is a comparison of monthly rates for renting GPUs on top cloud provider platforms. As we can see, E2E Networks provides vastly lower prices when compared with its competitors, for the same performance specs.

E2E Networks has been successful in delivering high-performance computing nodes at cost-effective prices, enabling businesses to reduce their hosting expenses by up to 40% without compromising on quality, security, and stability. (Refer to the images below.)


2. Highly Advanced Cloud GPUs and GPU Clusters
E2E Cloud provides instant access to advanced GPU clusters like InfiniBand-powered HGX H100 (8x, 16x, 64x clusters) and cloud GPUs H100, A100, L40S, and L4 on a 100% predictable prepaid billing model. These high-performance computing resources are essential for businesses looking to reduce training and inference expenses for AI and machine learning applications.
Amongst these, the HGX H100 cloud GPU cluster harnesses the incredible capabilities of anything between 8 to 64 H100 Tensor Core GPUs, linked via high-speed interconnects, making it one of the most formidable cloud GPU clusters available in the market.

(H100 GPU)
HGX 8xH100 configuration, for instance, supports a total of 640 GB of GPU memory and delivers an aggregate memory bandwidth of 24 terabytes per second. Offering an impressive 32 petaFLOPS of performance, it stands as the ultimate accelerated scale-up server platform for AI, high-performance computing (HPC) and Generative AI in particular.
The H100 cloud GPU is also equipped with a Transformer Engine designed to handle trillion-parameter language models. This technological advancement enables it to accelerate LLMs by more than 30 times compared to its predecessors, significantly enhancing the performance of Conversational AI.
3. The InfiniBand Technology
E2E offers InfiniBand with H100 GPU clusters, which makes it highly efficient to handle large-scale image, language and speech AI models. These AI models require significant computational resources and high-speed interconnectivity, which the InfiniBand tech makes possible.
InfiniBand is a high-speed, low-latency networking standard used for interconnecting servers, storage systems, and other high-performance computing (HPC) equipment. It is designed to provide high bandwidth, low latency, and efficient data transfer between devices.

(InfiniBand switches & cables)
Key features of InfiniBand include:
-
High bandwidth data rates, with link speeds ranging from 10 Gbps to 400 Gbps, depending on the version.
-
Low latency, which is crucial for high-performance AI computing applications.
-
RDMA (Remote Direct Memory Access) allows direct memory access between connected devices without involving the CPU, thus reducing overheads and improving performance.
4. NSE Listing and Data Sovereignty
E2E Networks, being NSE-listed, is fully compliant with Indian IT laws. This ensures that companies that host their cloud applications, or build and deploy their AI models on E2E Cloud, have the assurance and confidence that comes with a NSE listing.
5. TIR AI Platform
The TIR AI Platform, created by E2E networks, is a powerful cloud-based system that provides a wide range of tools and services for machine learning and artificial intelligence tasks. This platform allows users to easily create, deploy, and manage AI models.
The main features of the TIR AI Platform are:
-
Dashboard: A central place to keep track of AI projects, showing information about container usage, dataset readiness, running inference services, and pipeline runs.
-
Containers: The ability to start and manage containers, which are separate environments for building and running AI models.
-
Datasets: Tools for creating and handling datasets, which are essential for training and testing machine learning models.
-
Inference: Services dedicated to running inference tasks, where trained models make predictions on new data. The platform supports various frameworks like NVIDIA Triton, TensorRT-LLM, and PyTorch Serve, which provide optimized performance for different types of AI models.
-
Pipelines: Features to create and manage pipelines, allowing users to automate workflows for continuous integration and delivery of machine learning projects.
-
API Tokens: Options to generate and manage API tokens, enabling secure programmatic access to the platform's features.
-
Quick Access: An easy-to-use interface with shortcuts to commonly used features like launching containers, creating datasets, and starting inference services.
-
Activity Timeline: A log that records user activities and system events, providing transparency and helping with troubleshooting.
-
Foundation Studio, Integrations, and Settings: Extra tools and settings to customize and expand the capabilities of the platform, such as integrating with external services and adjusting project settings.
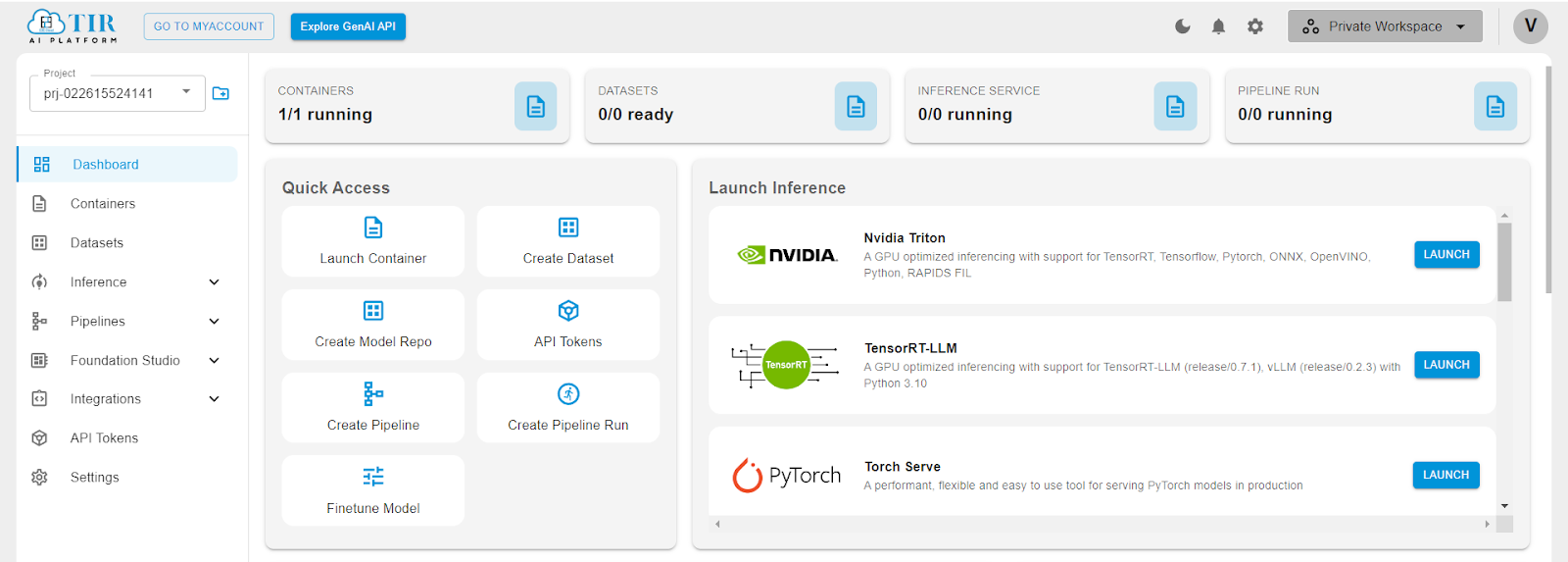
The platform supports many popular frameworks and tools used in the AI community, ensuring that it can handle a wide variety of use cases and preferences. The visual layout focuses on being user-friendly, with a clear navigation sidebar and a main panel that highlights the most important actions and information.
How Advanced GPUs Help Build Powerful AI Applications
1. LLM Training
Large Language Model (LLM) training involves the development and refinement of models capable of understanding and generating human-like text based on vast amounts of data. This process typically requires extensive computational resources and involves feeding the model a diverse dataset comprising billions of words from books, articles, websites, and other text sources.
The goal is to enable the LLM to learn complex language patterns, grammar, context, and nuances. During training, the model iteratively adjusts its internal parameters to minimize errors in its predictions, improving its ability to generate coherent, contextually appropriate responses.

This training can be highly resource-intensive, often running on powerful GPUs or TPUs, and can take weeks or even months, depending on the size of the model and the computational resources available.
The end result is a versatile tool that can be applied to a variety of tasks such as translation, summarization, question-answering, and more, significantly advancing the capabilities of AI in understanding and interacting using natural language.
Some of the top open-source LLMs out there are:
- Large-sized: Llama3-70b, Falcon-180b
- Medium-sized: Mixtral 8x7B
- Small-sized: Mistral-7b, Vicuna 13-B
Utilizing E2E’s Cloud GPU nodes or its TIR-AI platform, one can train these complex LLMs with ease.
2. Coding Copilots
Coding Copilots, powered by locally hosted Large Language Models (LLMs), are integrated directly into the development environment and operate on local servers, ensuring data privacy and faster response times. They assist programmers by providing code suggestions, debugging help, and even writing snippets of code based on the context of the project.

By fine-tuning the Coding Copilots, one can tailor the AI's learning and responses to the specific needs and data of the organization, offering a highly personalized and secure coding experience. Furthermore, using locally hosted models can be more cost-effective than subscribing to cloud-based services, making it a financially viable option for many businesses.
Some of the top coding LLMs include Code Llama, Starcoder, WizardCoder, and Phind-CodeLLama. These innovative tools are reshaping how developers interact with their coding environments, making software development more intuitive and efficient.
3. Fashion AI
AI image generation models like Stable Diffusion, DeepFloyd AI, Animagine XL, and extensions like ControlNet can automatically generate new clothing designs and patterns by learning from vast datasets of existing fashion images. This capability not only speeds up the design process but also inspires creativity by producing unique and innovative styles that might not have been conceived by human designers. Moreover, models like Stable Diffusion can be trained on subject images (on just a few images!) using the Dreambooth API. This allows for fashion enterprises to generate images on their own custom products.
Also, these models can simulate how fabrics and designs look on different body types or under various lighting conditions, providing a more accurate preview before the actual production begins. This application of AI in generating and manipulating images is allowing brands to experiment more freely and respond more swiftly to changing fashion trends.

Additionally, AI enables the creation of virtual fashion influencers—digitally rendered personas who interact with real audiences on social media platforms. These influencers can be customized to exhibit specific styles, trends, or brand identities without the logistical constraints of traditional photoshoots.
4. Media and Entertainment AI
Key AI technologies in this sector include:
-
Speech-to-Text AI: Converts spoken language to written text, improving accessibility and searchability for media content.
-
Text-to-Speech AI: Transforms written text into natural-sounding speech, enhancing user engagement and making content accessible to those with visual impairments. Example - Whisper Speech.
-
Video Generation AI: Automates the creation of videos from text descriptions or modifies existing footage, streamlining production and enabling creative expression. Example - Stable Video Diffusion.

(Video generated by Stable Video Diffusion)
- Audio Generation AI: Produces music and sound effects without traditional recording; useful in gaming, film, and virtual reality to enhance immersive experiences. Example - Audiocraft by Meta.
These AI applications are changing how media content is created, accessed, and delivered, meeting diverse audience needs and opening up new creative possibilities.
Final Words
E2E Networks has emerged as an AI-first player in the Infrastructure as a Service (IaaS) market, offering high-performance computing resources at competitive prices.
The company's focus on advanced GPU clusters, InfiniBand technology, data sovereignty, and compliance with Indian IT laws has positioned it as an attractive choice for businesses seeking to scale their operations and build powerful AI applications.