Generative AI is no longer just a research frontier. It is rapidly becoming the backbone of smart applications across industries. At E2E Cloud, we have made it easier than ever to bring Generative AI into your projects with the TIR Foundation Studio’s GenAI APIs.
In this blog, we will talk about TIR GenAI APIs and walk you through a simple step-by-step guide to build a chatbot using the Llama 3 8B Instruct model accessible through the APIs on TIR Foundation Studio.
What Are TIR GenAI APIs?
TIR Foundation Studio provides API access to powerful open-source and proprietary AI models like:
- Text generation LLMs for natural language tasks like chat, summarization, coding help (eg, DeepSeek V3 0324, Llama 4 Maverick 17B 128E Instruct, Gemma 3 27B-it)
- Vision models (like Stable Diffusion for image generation)
- Speech and multimodal LLMs (eg, whisper-large-v3)

These APIs are:
- Hosted on high-performance GPUs (H100, A100) for low-latency, high-throughput inference.
- Scalable on demand, suitable for both prototyping and production-scale applications.
- Secure and private, ensuring data does not leave sovereign cloud boundaries when required.
Key Benefits of the TIR GenAI APIs
| Benefit | Description |
|---|---|
| API-first Access | Consume powerful AI models over a simple API without needing to manage infrastructure. |
| Optimized for Enterprises | Supports production use cases with predictable performance. |
| Flexible Model Choices | Choose from instruction-tuned, chat-optimized, or multimodal models. |
Quick Try with TIR Foundation Studio Playground
Before getting into the coding part, you can explore the Playground in TIR Foundation Studio, a no-code interface to experiment with models. Simply type a prompt, adjust parameters like temperature or top-p, Max Tokens, Presence Penalty, and Frequency Penalty to see how the model responds in real-time.
You can also use the Playground to refine prompts or benchmark responses before embedding the API into your application.
Building a Llama 3.1 8B Chatbot Using TIR GenAI API
In this tutorial, we’ll build a real-time chatbot UI using Gradio powered by the Llama 3 8B Instruct model via the TIR Foundation Studio API.
Prerequisites:
Ensure you have:
- Python 3.8+
- TIR API key and endpoint for Llama 3 8B Instruct
- Packages: openai, gradio
Install the dependencies:
pip install openai gradio
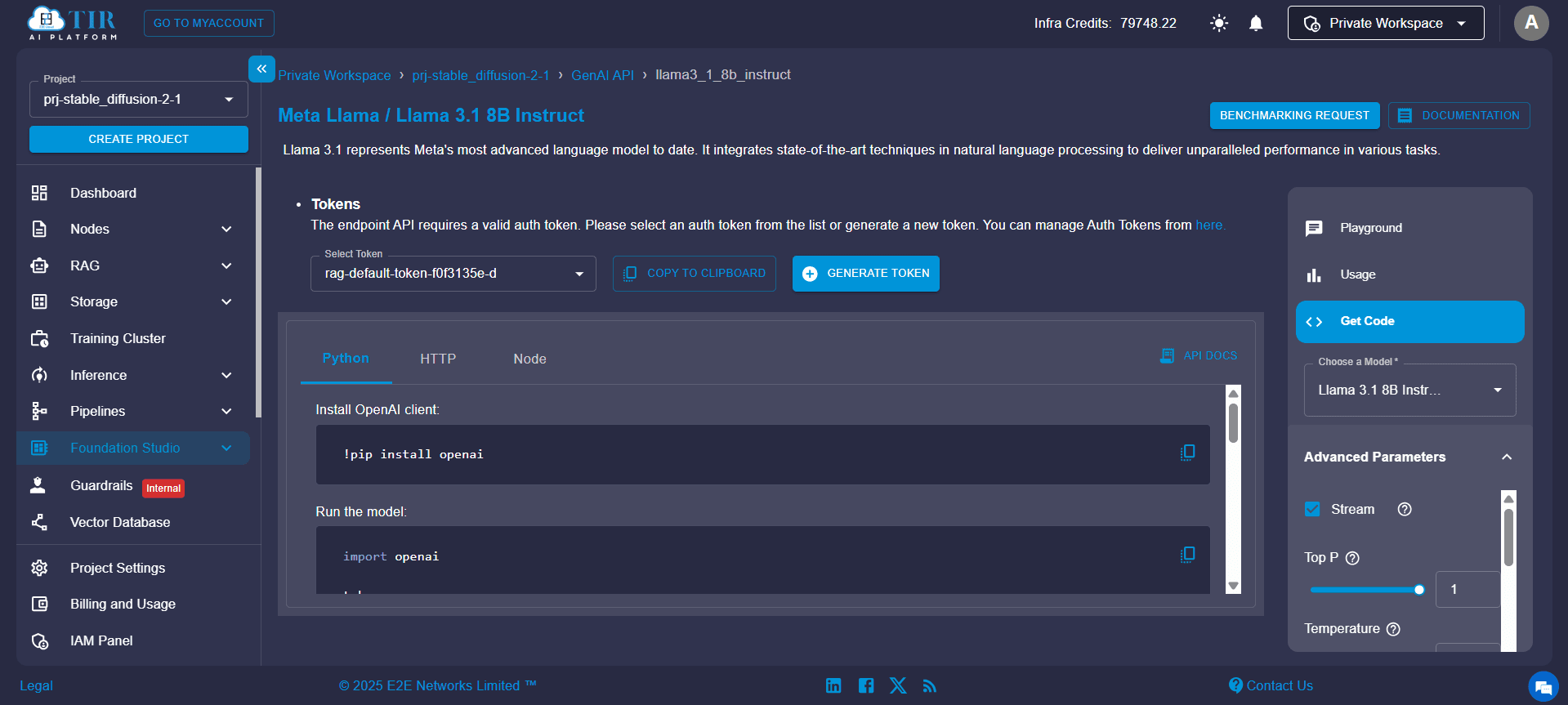
Step 1: Generate API Token in TIR Foundation Studio
Before calling any API, you’ll need to generate an authentication token within the TIR Foundation Studio.
- Navigate to Foundation Studio > GenAI API.
- Select the model you want to use (e.g., Llama 3.1 8B Instruct).
- Go to the “Get the Code” tab and generate the token.
Once generated, the token can be selected from the dropdown and copied directly to your clipboard. You’ll need this token to authorize your API requests when building applications.
Step 2: Set up Your API Connection
Replace the placeholder with your TIR API key and endpoint:
import openai
openai.api_key = "<YOUR_E2E_API_KEY>"
openai.base_url = "https://infer.e2enetworks.net/project/p-6101/genai/llama3_1_8b_instruct/v1/"
MODEL_NAME = "llama3_1_8b_instruct"
Step 2: Define the Chat Logic
We’ll maintain chat history and stream responses from the model:
def chat_with_llama3(history):
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
reply_text = ""
try:
response = openai.chat.completions.create(
model=MODEL_NAME,
messages=messages,
temperature=0.5,
max_tokens=1024,
top_p=1,
frequency_penalty=0,
presence_penalty=1,
stream=True
)
for chunk in response:
if hasattr(chunk, "choices") and chunk.choices:
delta = chunk.choices[0].delta
if hasattr(delta, "content") and delta.content:
reply_text += delta.content
except Exception as e:
reply_text = f"Error: {str(e)}"
history.append({"role": "assistant", "content": reply_text})
return history
Step 3: Create an Interactive Gradio UI
This will render a simple chatbot interface:
# Gradio UI
with gr.Blocks() as demo:
gr.Markdown("## Ask Llama 3.1")
chatbot = gr.Chatbot(type="messages", label="Llama 3 Chat")
user_input = gr.Textbox(placeholder="Type your message...", label="Message")
state = gr.State([]) # chat history
clear = gr.Button("Clear")
def user_submit(message, history):
history.append({"role": "user", "content": message})
return "", chat_with_llama3(history)
user_input.submit(user_submit, [user_input, state], [user_input, chatbot])
clear.click(lambda: ([], []), None, [chatbot, state])
demo.launch()
Step 4: Run It Locally
Save the code in a file, e.g., llama3_chatbot.py, and run the Python file:
python llama3_chatbot.py
You’ll get a Gradio web UI where you can interact with Llama 3 in real-time.
Industrial Use Cases with TIR GenAI APIs
With a solid API foundation in place, you can extend your chatbot or generative AI application to solve real-world challenges across industries. Here are some practical applications where TIR’s GenAI APIs, especially LLaMA models, can deliver a transformative impact.
Healthcare Assistants
Generative AI can be a powerful ally in healthcare by serving as a conversational assistant for patients and practitioners. Using instruction-tuned LLaMA models, you can deploy a secure chatbot that helps triage patient symptoms, summarize electronic health records (EHRs), and respond to common post-consultation FAQs. Hosting the solution on E2E’s Sovereign Cloud ensures compliance with India's healthcare data protection standards, making it a reliable choice for telemedicine platforms and hospitals.
BFSI Knowledge Agents
In the banking, financial services, and insurance (BFSI) sector, GenAI APIs can be used to automate internal knowledge management and customer-facing support. For example, you can build agents that explain policy details, provide personalized financial planning tips, or answer regulatory compliance queries. By fine-tuning Llama models on domain-specific documents such as financial statements, policy manuals, or RBI guidelines, you can dramatically improve the precision and relevance of responses.
Manufacturing Operations Advisor
In industrial settings, AI models integrated into operational dashboards can assist workers and supervisors by answering technical queries about machinery, interpreting SOPs, and even providing troubleshooting help based on historical logs. With TIR’s low-latency GPU nodes, manufacturers can deploy these models to deliver real-time inference, enabling predictive maintenance alerts and workflow optimization directly on the shop floor.
Enterprise Knowledge Management
Large organizations often struggle with fragmented information and inconsistent onboarding processes. With GenAI APIs from TIR, you can build internal knowledge assistants trained on your company's documentation, policies, and playbooks. These assistants can help employees get quick answers to routine questions, surface best practices from internal wikis, and streamline onboarding by providing contextual guidance to new hires; all through a conversational interface.
Media and Content Generation
For creative teams in media, marketing, or entertainment, GenAI APIs unlock powerful content workflows. Using models like Llama 3 for text and Stable Diffusion APIs for visuals, teams can generate article drafts, automate social media captions, or create visual assets for campaigns. With human-in-the-loop feedback mechanisms, these models can be guided to align with brand voice and editorial tone, significantly speeding up ideation and production cycles.
Building and Deploying Custom GenAI Solutions on TIR
TIR Foundation Studio lets you build custom GenAI solutions by fine-tuning models like Llama on proprietary datasets directly within its high-performance GPU environment. You can integrate vector databases like Qdrant for retrieval-augmented generation (RAG), enabling context-aware responses. With built-in support for API autoscaling, load balancing, and optimized inference, TIR makes it easy to deploy scalable, production-ready AI applications.
Start building with TIR Foundation Studio today: tir.e2enetworks.com