Gemma 7 b is a good candidate to customize as a powerful AI model without getting lost in lines of code? Fine-tuning large language models (LLMs) like GEMMA-7 B is no longer the subject of research. The intuitive, no-code interface of TIR's Foundation Studio enables you to craft custom AI models efficiently with your proprietary data, leveraging the simplicity of LoRA (Low-Rank Adaptation).
This guide will walk you through 10 simple steps to fine-tune your very own gemma-7B-it model using TIR. You can build a bespoke chatbot as an example, an Agentic customer support agent, or a self-paced Python tutor, just for your specific needs. Let's get started!
Step 1: Fire Up the TIR Foundation Studio
Head over to the TIR Foundation Studio and log in. This is your command center, where you'll pick your model, upload data, configure training, and monitor progress. It's designed to be super user-friendly, so you'll feel right at home.
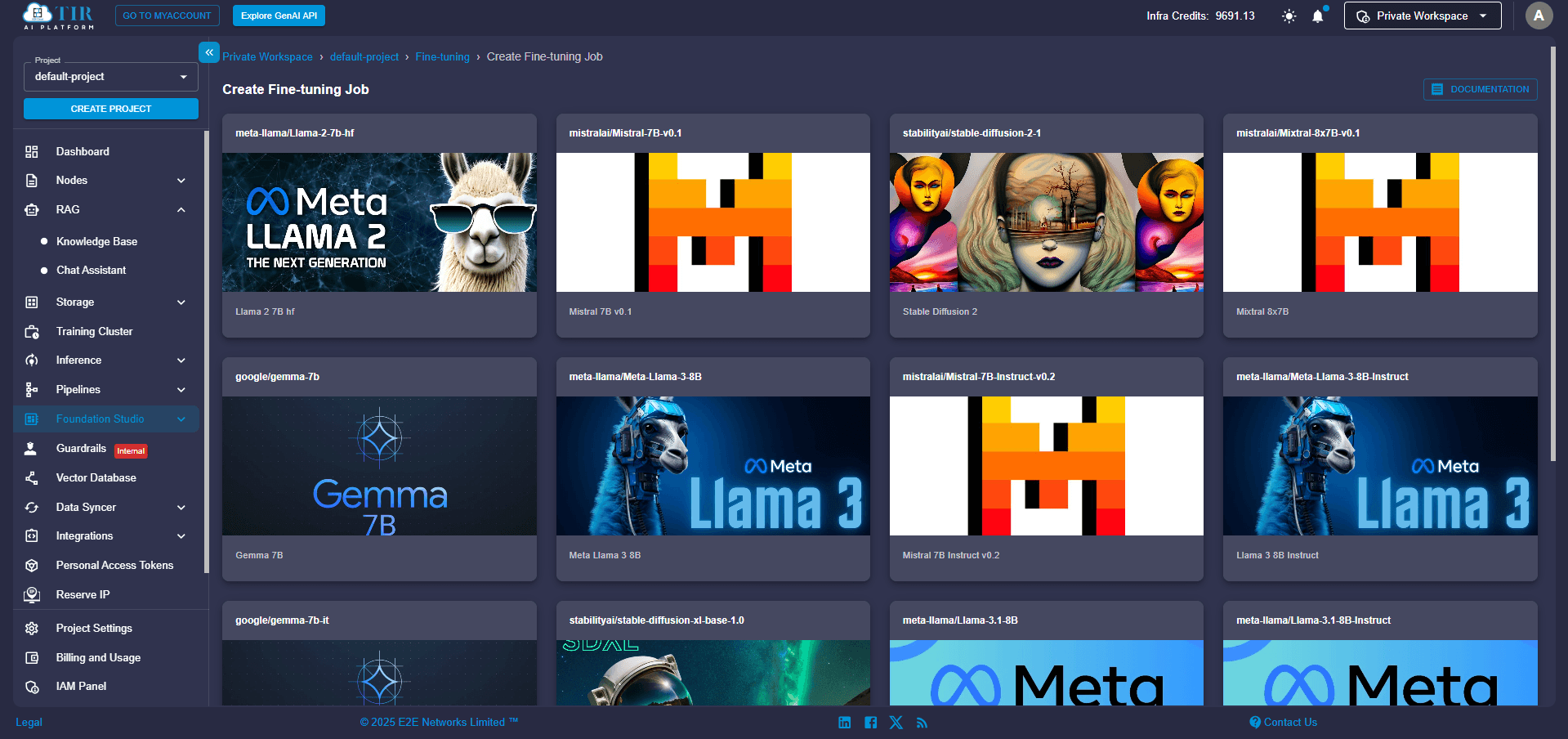
Step 2: Pick Your Preferred Model
From the list of available pre-trained models, select gemma-7B-it. This version is a reasonable choice, especially when you're looking to fine-tune with smaller datasets using LoRA, as it is already optimized for following instructions.
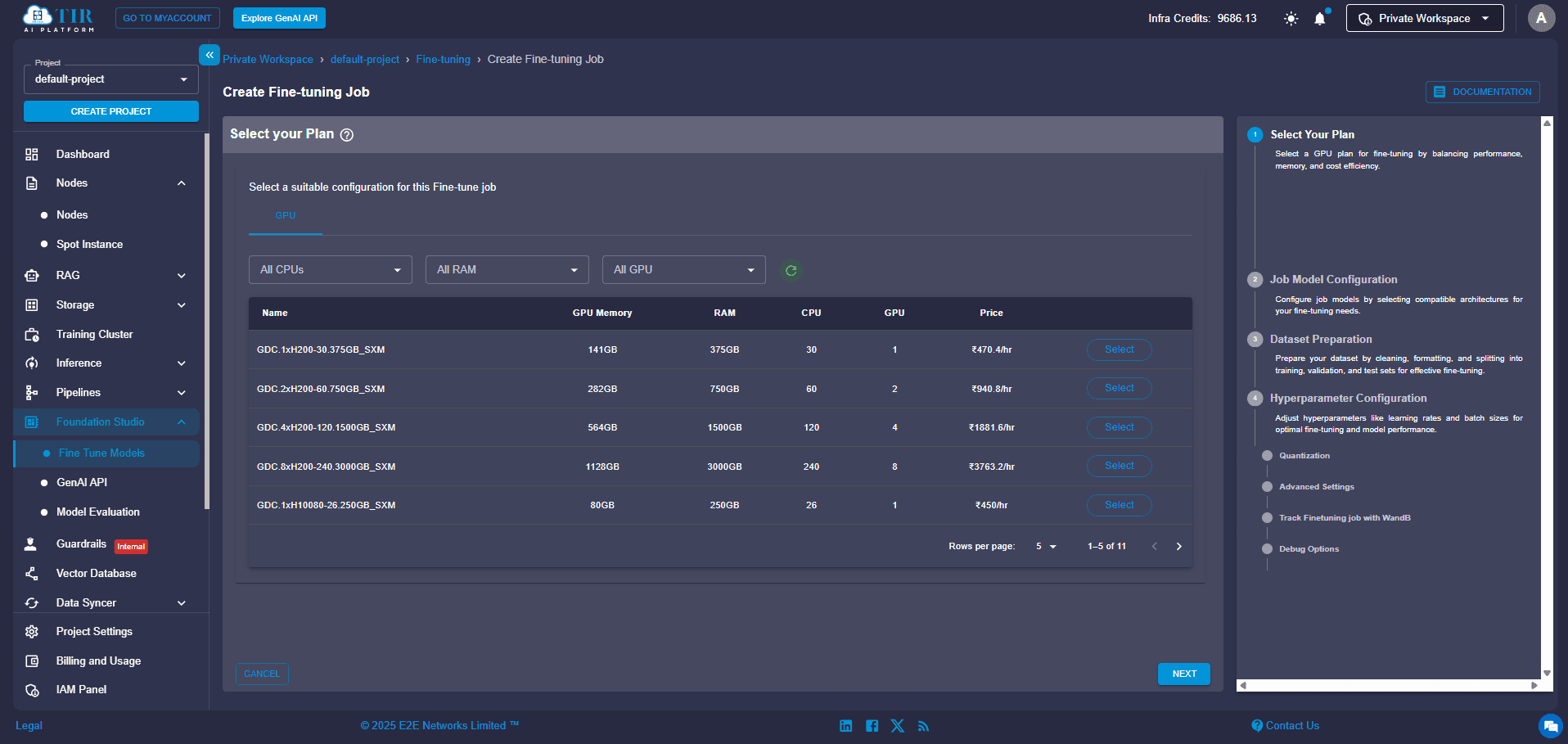
Step 3: Choose Your Engine (Compute Plan)
Next, you'll need to select a compute instance that is up to the task. For optimal performance, we highly recommend:
- GPU: NVIDIA A100 80GB (a top-tier graphics processing unit built for AI)
- Memory: 115GB
Pick the plan that aligns best with your budget and how long you expect your training to run. Think of it as choosing the right engine for your custom AI.
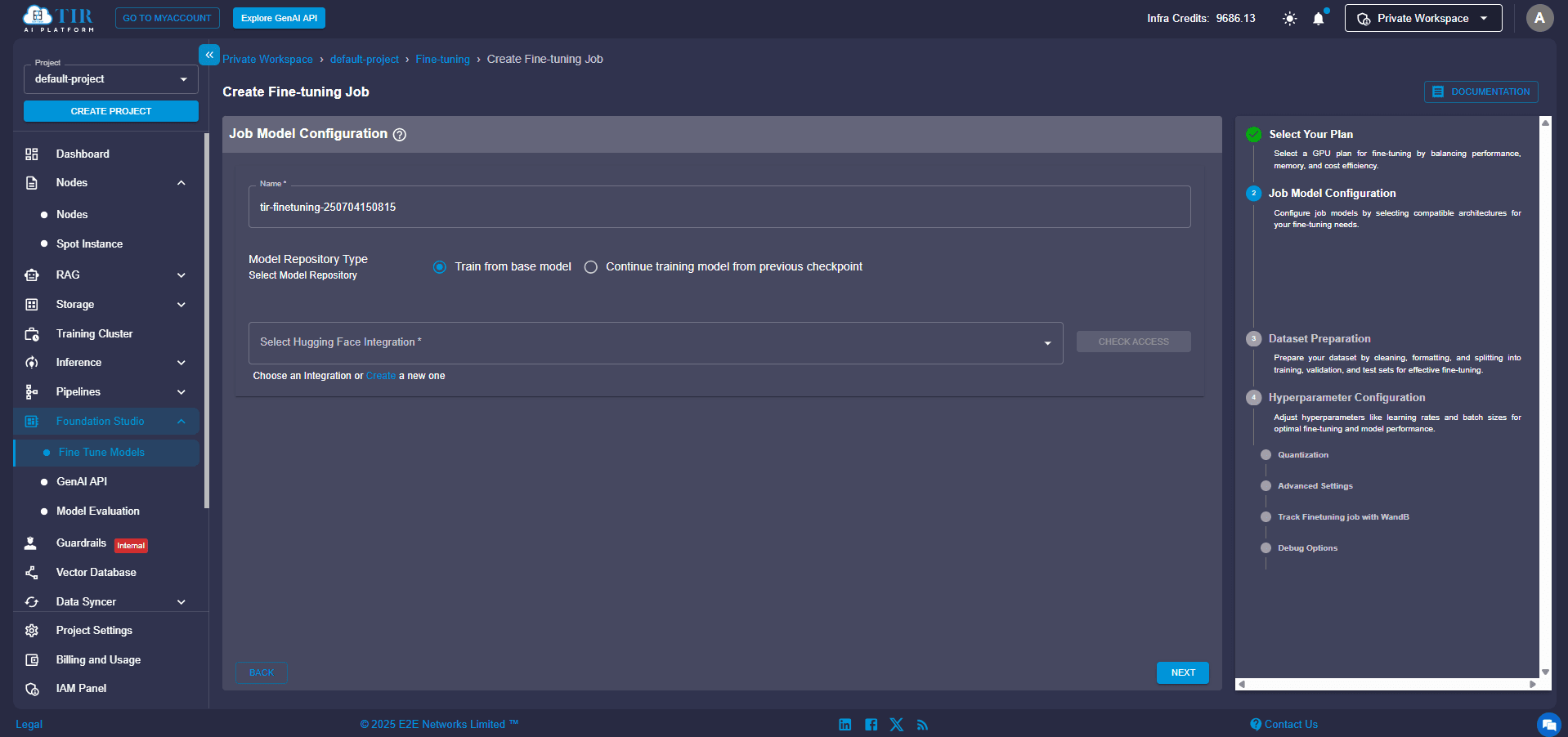
Step 4: Enable Training & Connect to Hugging Face
Time to get things moving! Click on “Train the Base Model”. You'll be prompted to authenticate with your Hugging Face access token. If you haven't linked your account yet, don't worry – just click “Create New” to generate and add a token. This token is crucial for pulling the base model weights (the AI's learned knowledge) and, if you choose, pushing your fine-tuned model back to your Hugging Face repository.
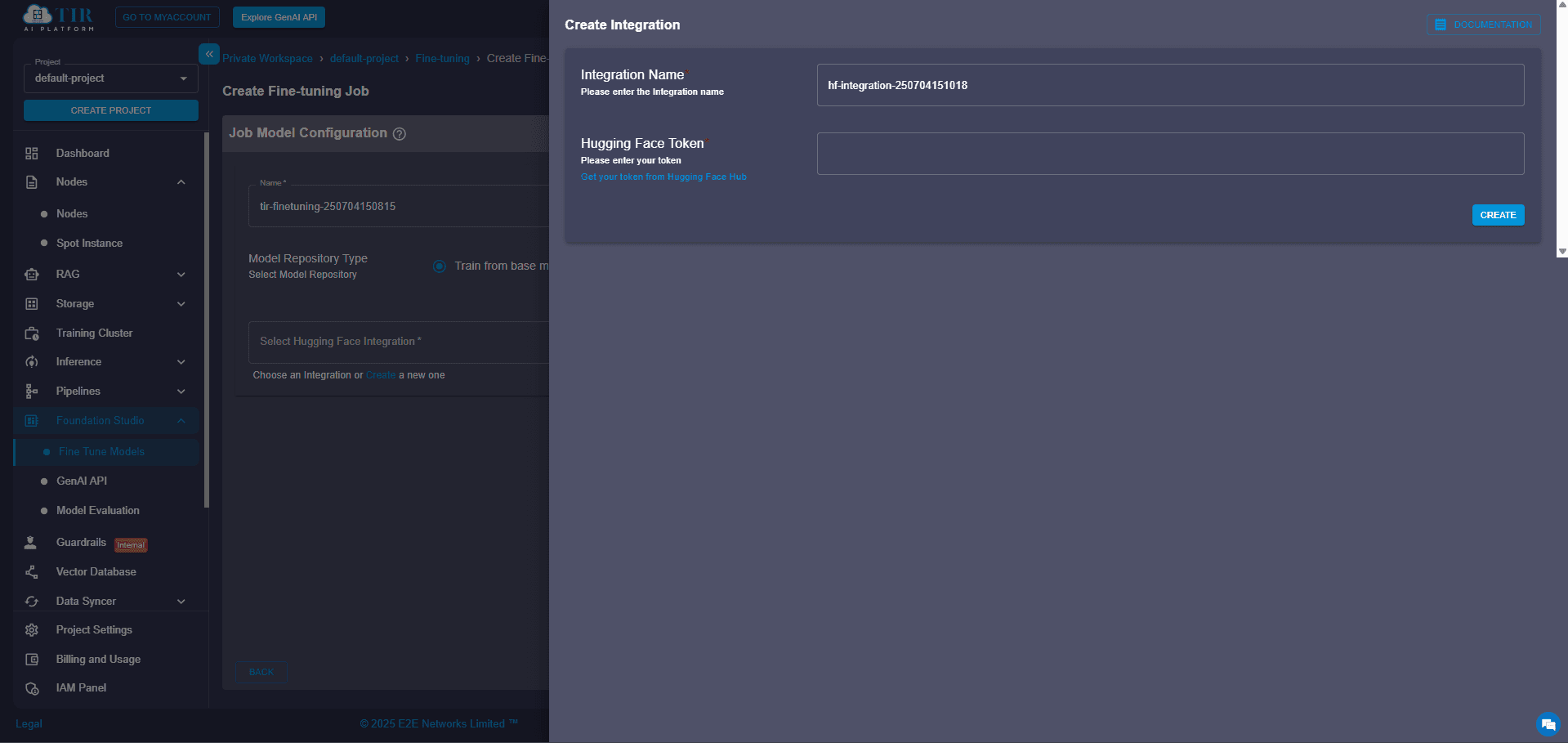
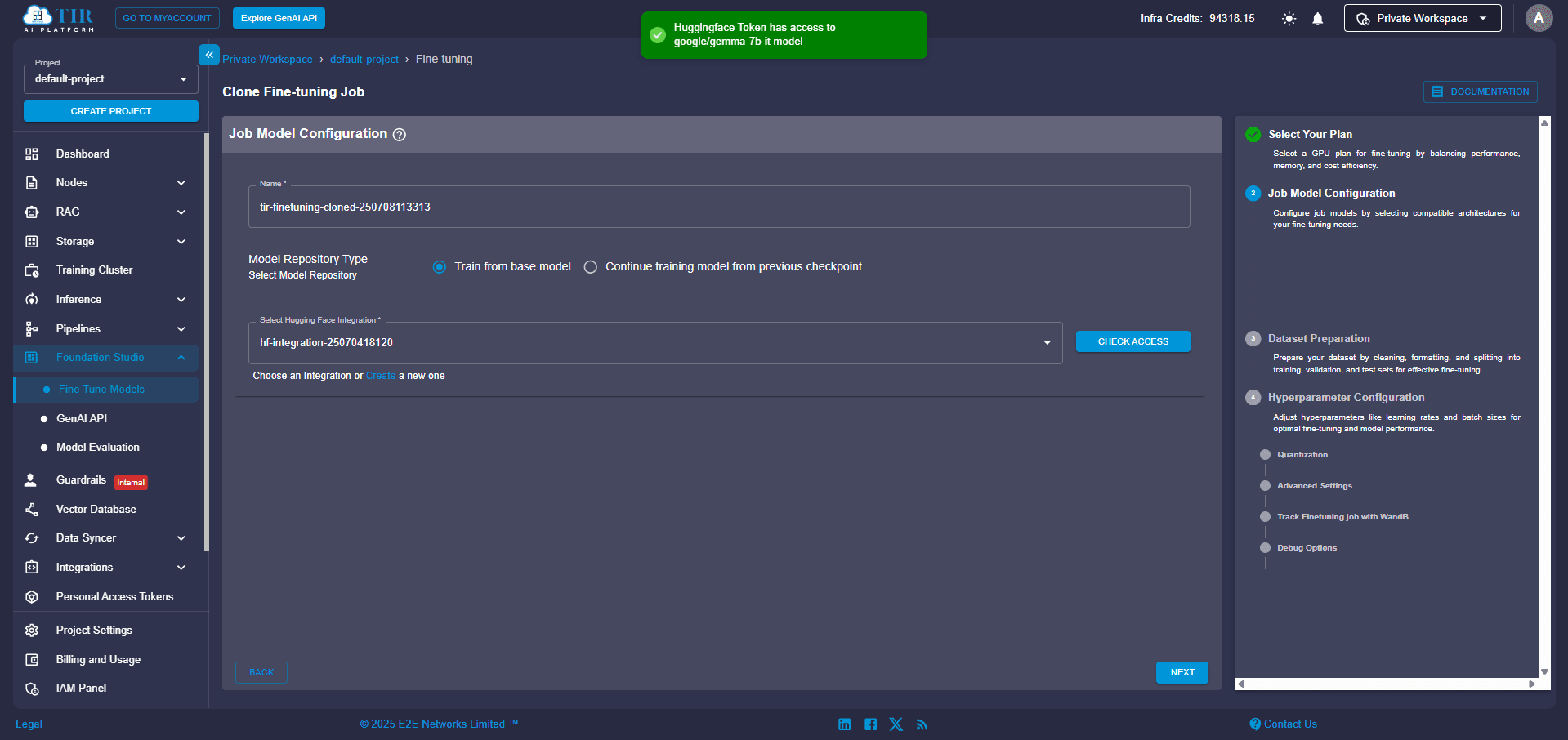
Step 5: Check Your Hugging Face Access
Before proceeding, take a quick moment to ensure your token is valid and that you have the necessary permissions for the model you're fine-tuning. A quick check here can save you headaches down the line!
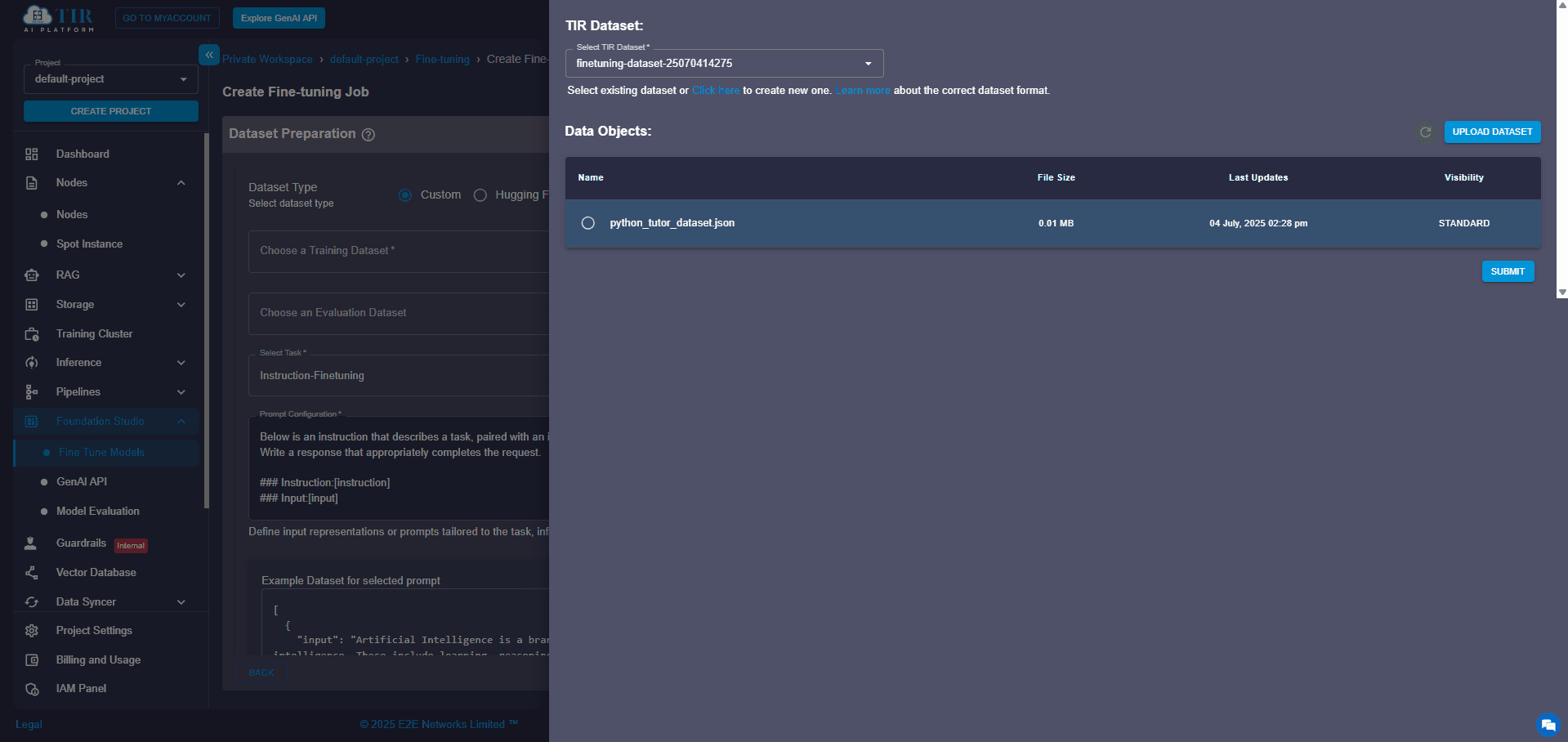
Step 6: Upload Your Data (Training & Optional Evaluation)
Now for the memory of your custom model: your dataset! Prepare your data in the following format. For instance, if you're building a question-answering model, a JSON format like this works perfectly:
{
"question": "What happens if an exception is not caught?",
"answer": "The program crashes."
},
Simply upload your file directly through the UI. You can also add an evaluation dataset to monitor the quality of your training as it progresses. You can use the python_code_instructions_18k_alpaca dataset to train your Python tutor chatbot without needing any additional preprocessing.
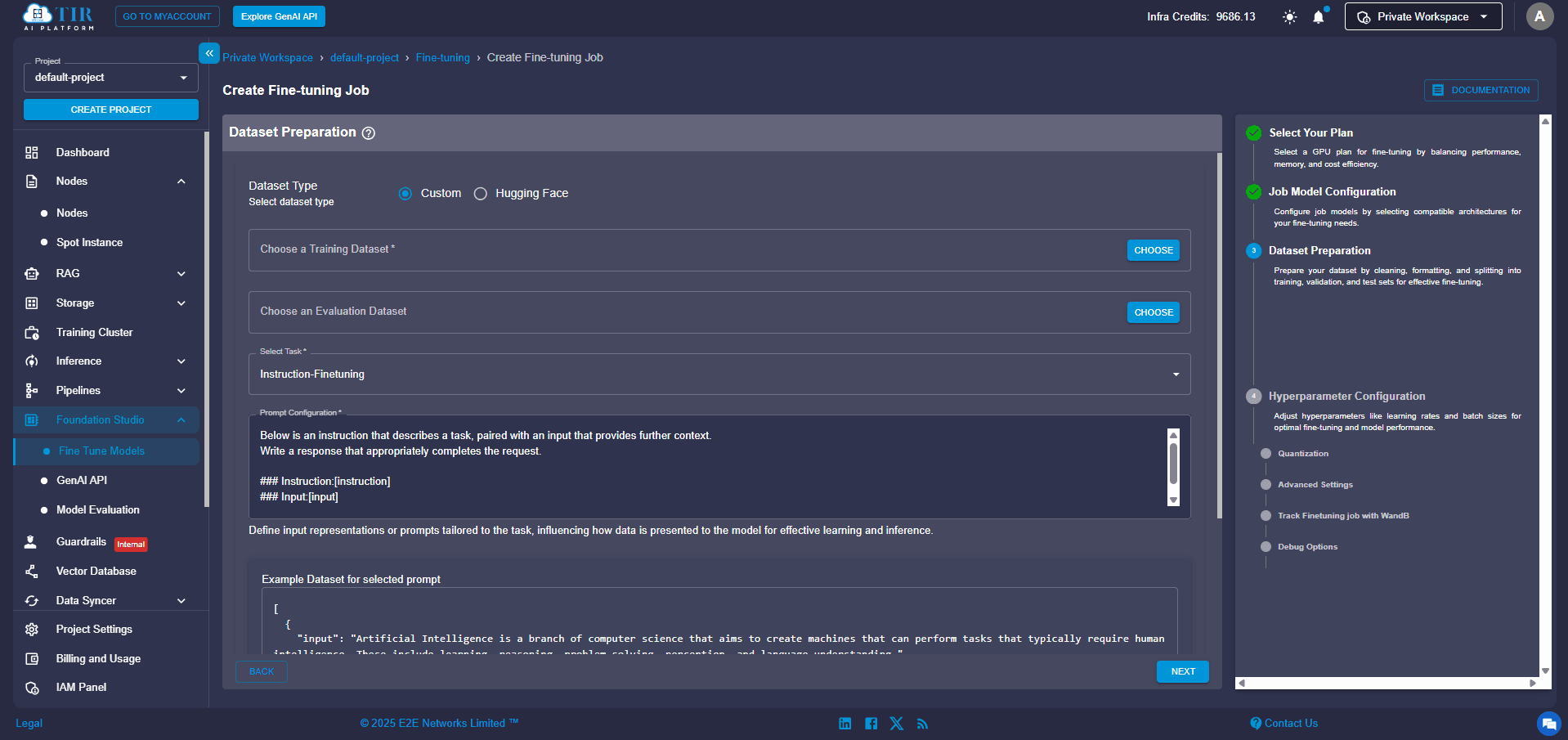
Step 7: Tell Your Model What to Do (Define the Task Type)
From the available options, select the specific task for which you're fine-tuning your model. In our example, you'd choose “Question Answering”. This helps TIR apply the correct training head and preprocessing logic, making sure your model learns exactly what you want it to do.
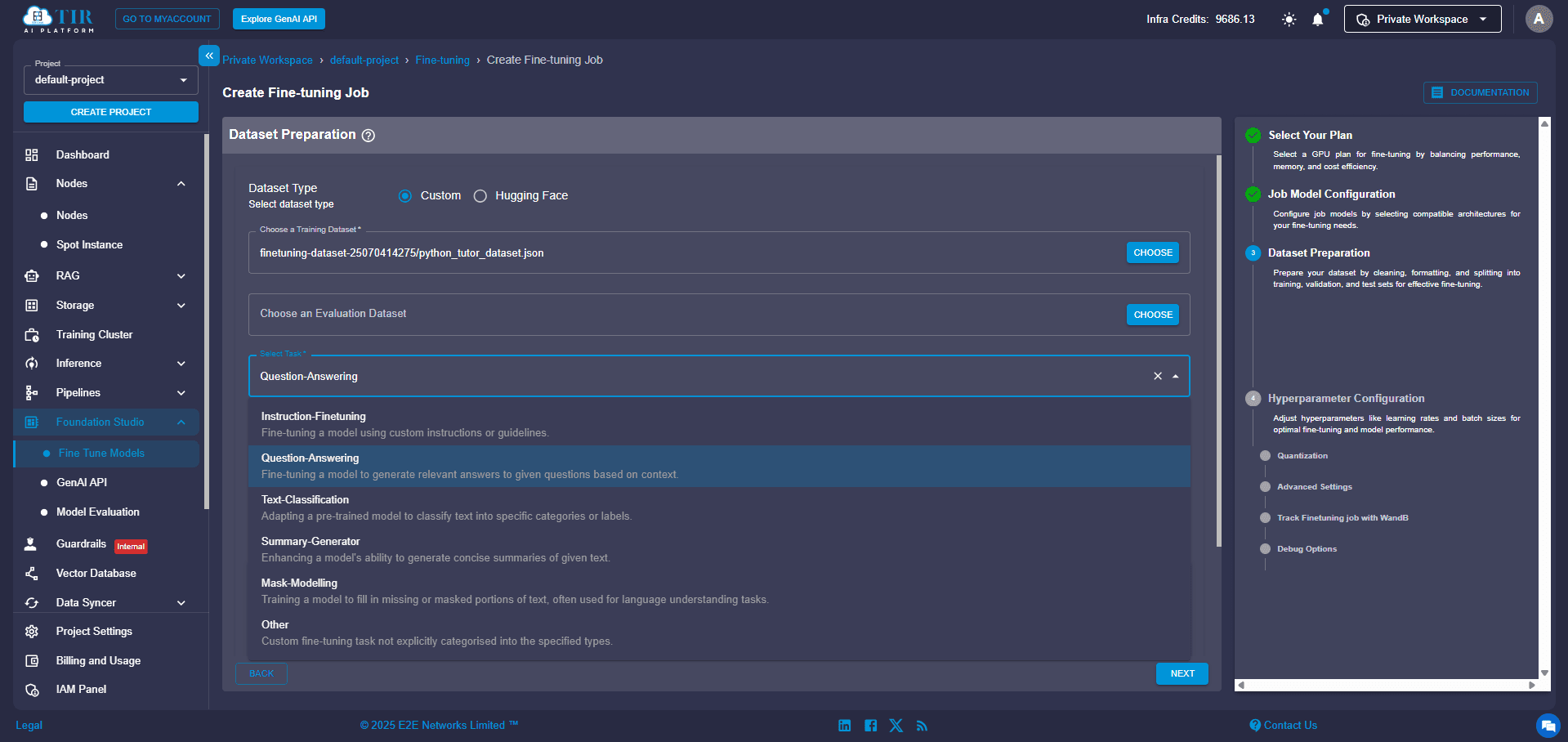
Step 8: Fine-Tune Your Training Parameters
This is where you customize the learning process. You'll want to configure these settings:
- Training Type: Select Parameter-Efficient Fine-Tuning (PEFT). This is highly recommended because it significantly optimizes GPU usage and training time. Instead of updating the entire massive model, LoRA introduces small, trainable "adapter" layers, making the process much more efficient.
- Epochs: Set this based on your dataset size (e.g., 3–10 epochs is a good starting point). An epoch means the model has seen your entire training dataset once.
- Learning Rate: The default values are often sufficient, but you can tweak them manually if you're feeling adventurous. This controls how big of a "step" the model takes when adjusting its internal parameters during training.
- LoRA Bias: This lets you choose how much of the model should be updated during fine-tuning. By selecting LoRA bias, you're telling the model to adjust only the small bias components instead of the full weight matrices. This makes training even more lightweight and faster, with minimal impact on performance, which is ideal when you're working with limited GPU resources or want quicker results.
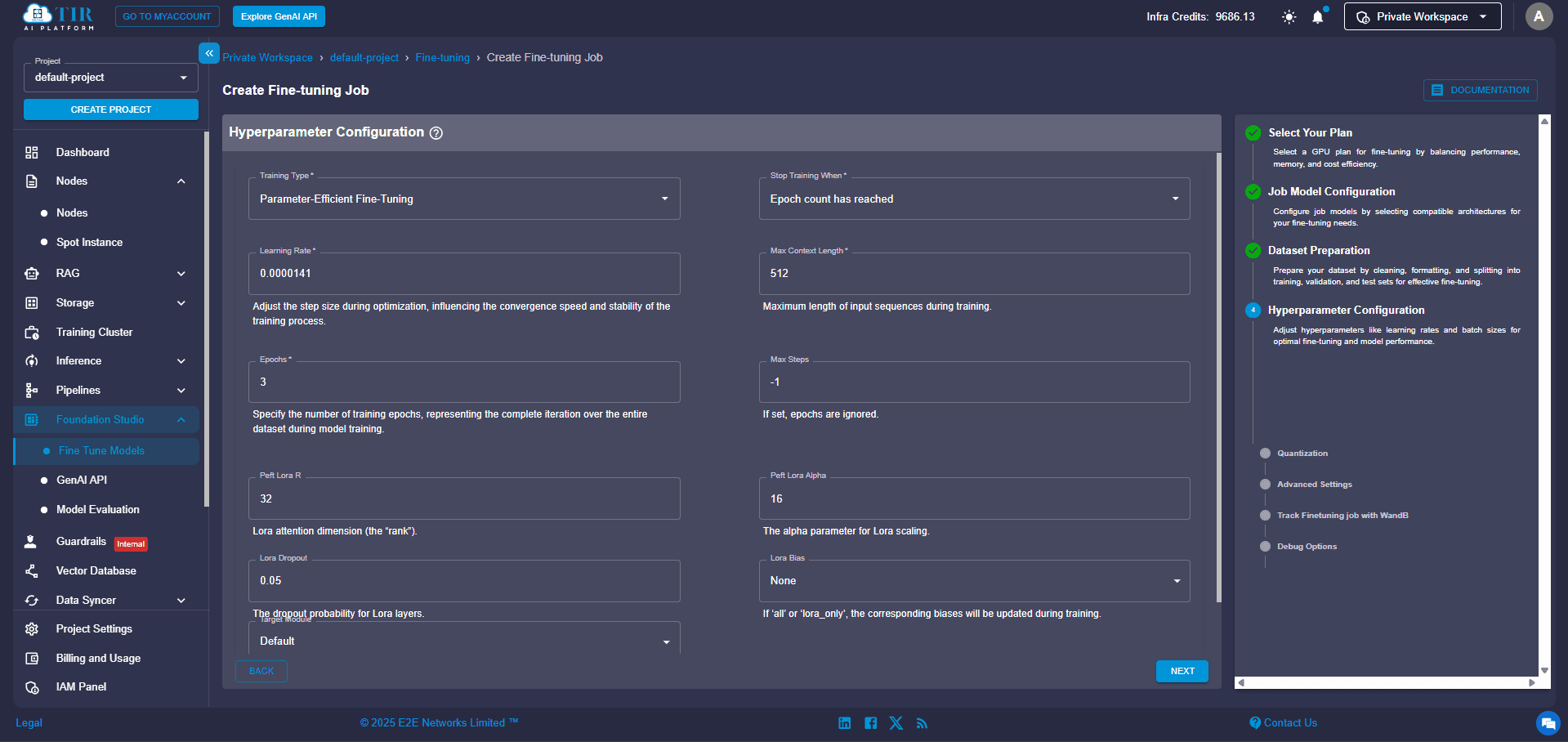
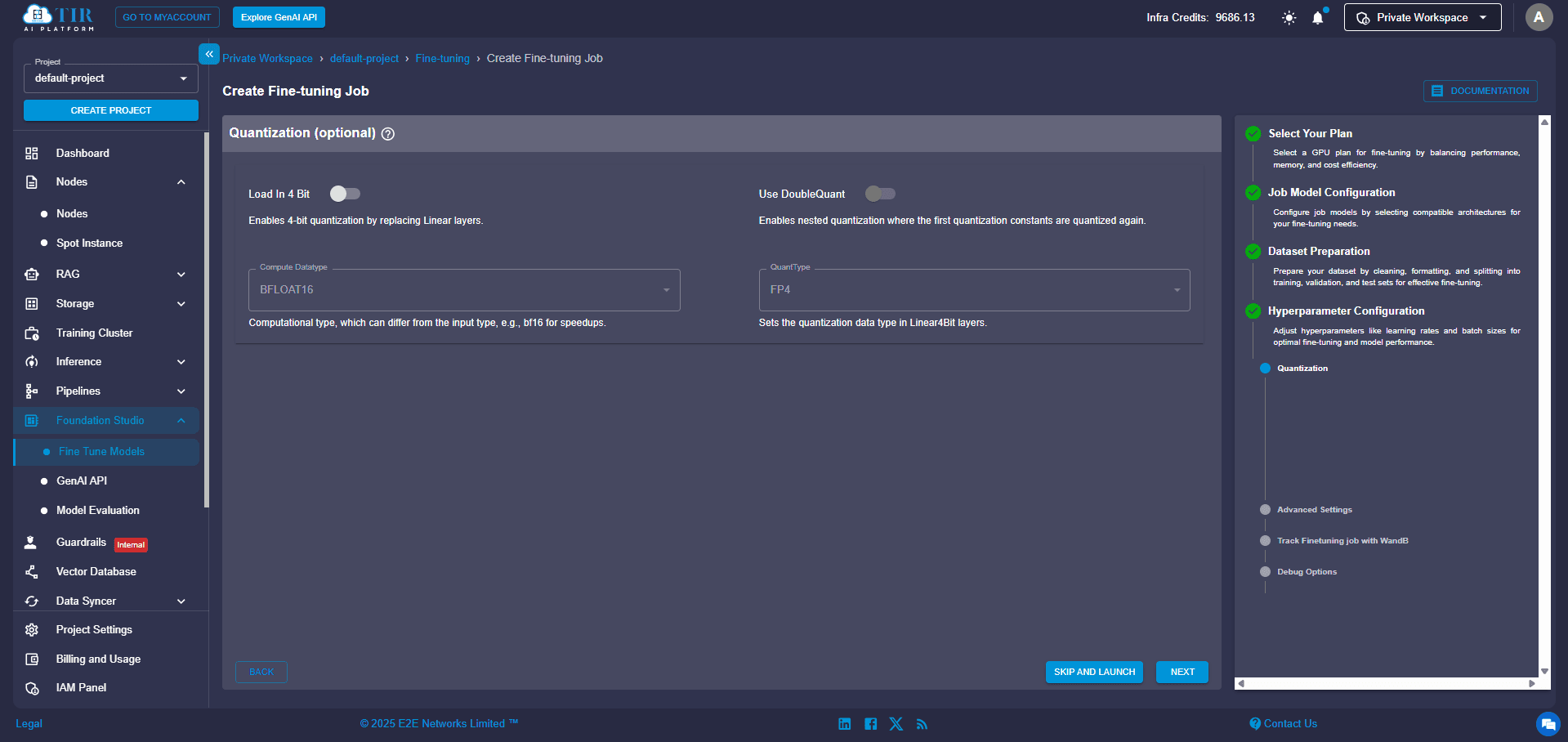
Step 9 (Optional): Unlock Advanced Settings
For those who want more control, the Advanced Configurations offer deeper customization:
- Quantization Type: A technique to make the model smaller and faster by using fewer bits to represent its data.
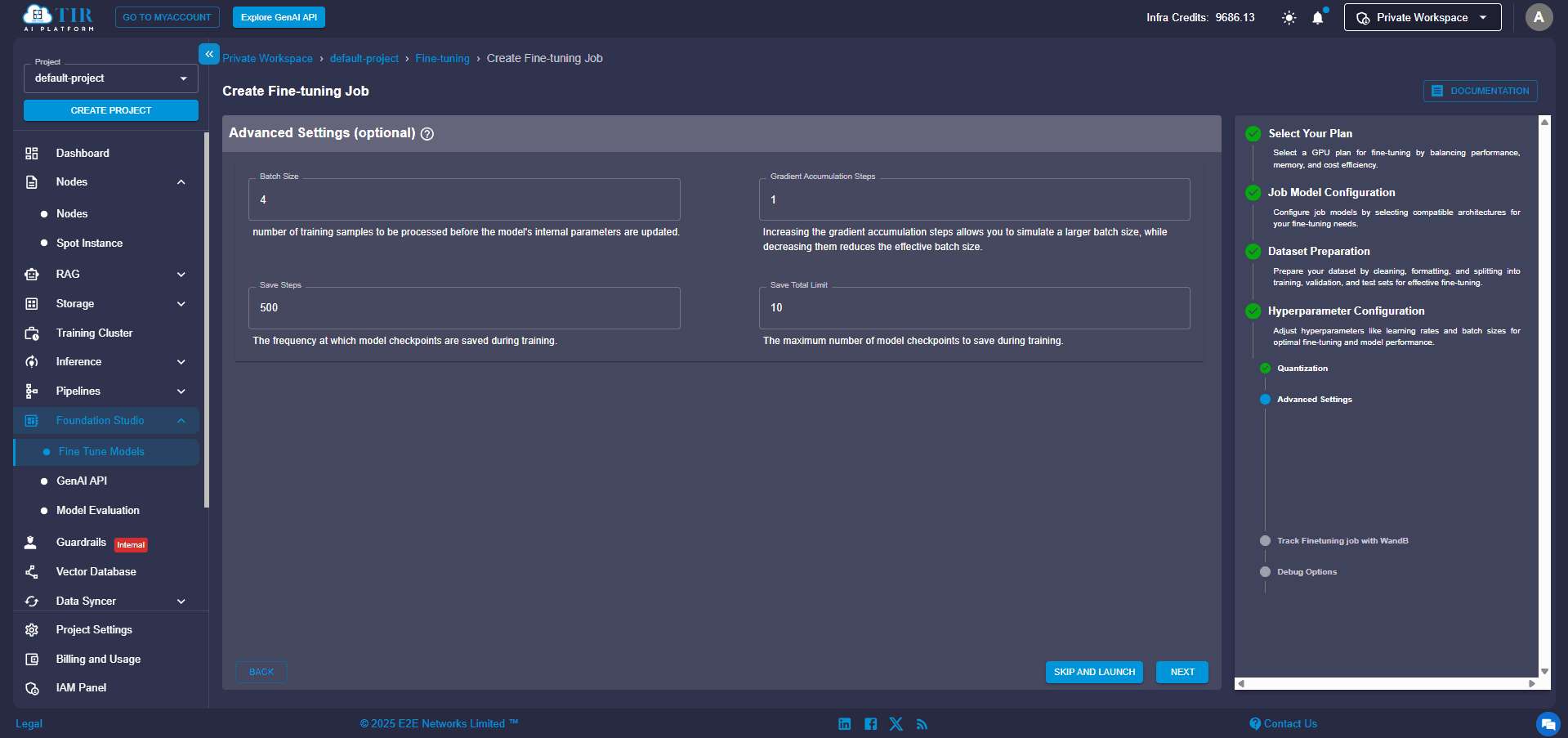
- Batch Size: The number of examples the model processes at once.
- Gradient Accumulation Steps: A way to simulate larger batch sizes if your hardware has memory limits.
- Checkpoint Saving Frequency: How often the system saves your model's progress during training.
- Weights & Biases (WandB) Tracking: A powerful tool for monitoring and visualizing your training metrics in real time.
- Debugging Flags: Specific settings to help diagnose any issues during training.
These options give you fine-grained control over performance and how you monitor your model's training journey.
Step 10: Review and Launch Your Model
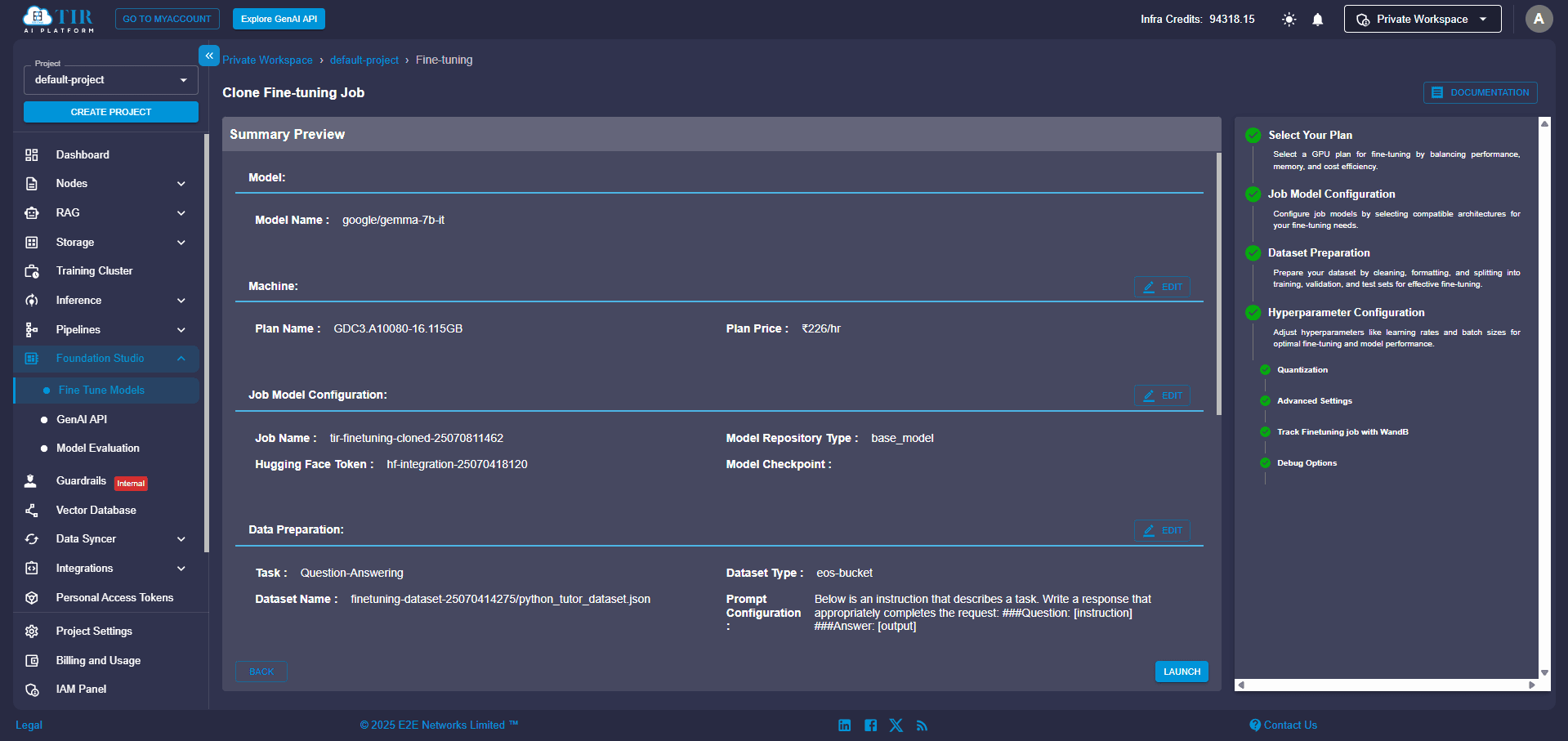
You're almost there! Before you hit that launch button:
- Review all your selections in the summary pane.
- Confirm your compute instance, chosen model, datasets, and hyperparameters.
- Once you're satisfied, click Launch to kick off your training job!
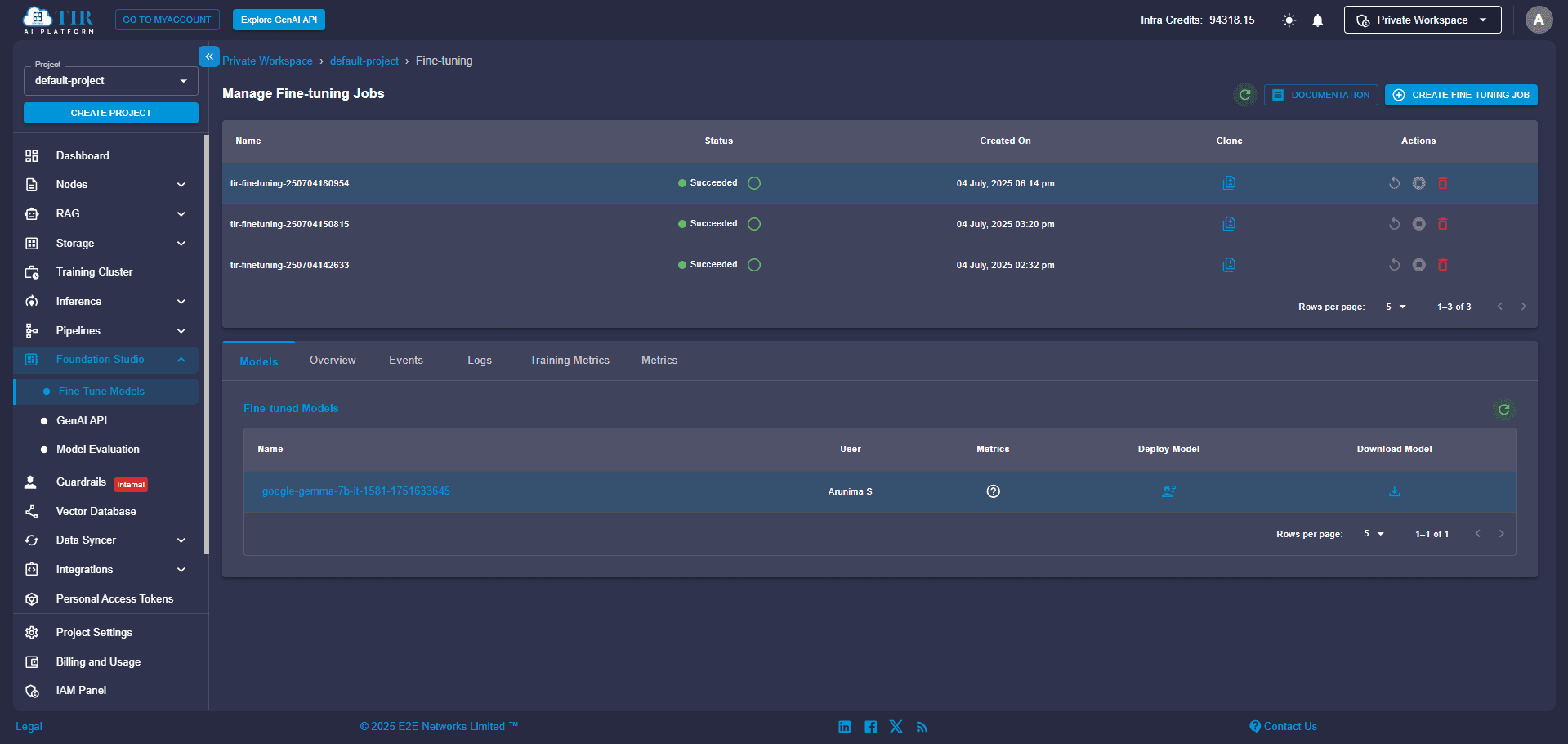
You will see real-time logs, metrics, and model events directly in your dashboard. Once training is complete, your new fine-tuned model will be ready for download or deployment.
No-Code Model Fine-Tuning Made Easy with E2E Cloud’s TIR Platform
TIR’s no-code fine-tuning interface makes it easy for anyone to unlock the full potential of AI. Finetuning models like Gemma-7 B becomes a straightforward process, enabling customers to adapt powerful language models to their specific domains. By leveraging LoRA for efficient parameter tuning, you can build high-impact, domain-specific models ready for real-world deployment, even when working with smaller datasets. This allows your business to deliver tailored AI capabilities quickly and cost-effectively.
Ready to build your custom AI? Begin your journey with E2E Cloud's AI model deployment platform and unlock the potential of language models!