Large language models (LLMs) are used everywhere from code generation to customer support. ChatGPT, a GenAI chatbot that has made its way into our daily lives, runs on powerful LLMs like OpenAI-GPT models. While they’re powerful, users often face issues like outdated knowledge or even made-up facts known as “hallucinations”. That’s where Retrieval-Augmented Generation (RAG) comes in. RAG helps LLMs improve their accuracy by significantly reducing hallucinations, letting them pull in up-to-date information from trusted sources.
In this guide, we’ll walk you through how RAG works and why it’s a game-changer for getting smarter, more reliable answers from LLMs.
What Is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is a technique that combines large language models (LLMs) with external data sources to improve the relevance and accuracy of responses.
Instead of relying only on the model’s pre-trained knowledge, RAG allows the LLM to retrieve domain-specific information from a given knowledge base, documents, or APIs. By tailoring the output to specific queries and enhancing factual accuracy, this helps reduce hallucinations. RAG, with the help of APIs and streaming databases, bridges the gap between static knowledge and dynamic information needs by grounding answers in current, reliable data.
Why is RAG Useful for LLMs?
LLMs are trained on large datasets, but their knowledge may not include recent or domain-specific information. RAG solves this by allowing the model to fetch relevant, real-time data from trusted sources, with the help of APIs and streaming databases. This greatly reduces factual errors, generating more accurate and contextually relevant responses.
By grounding answers in up-to-date and authoritative information, RAG enhances user trust and ensures the model can handle specialized or time-sensitive queries much more reliably than a standalone LLM.
The following image depicts the process, from submitting the query to producing a response.
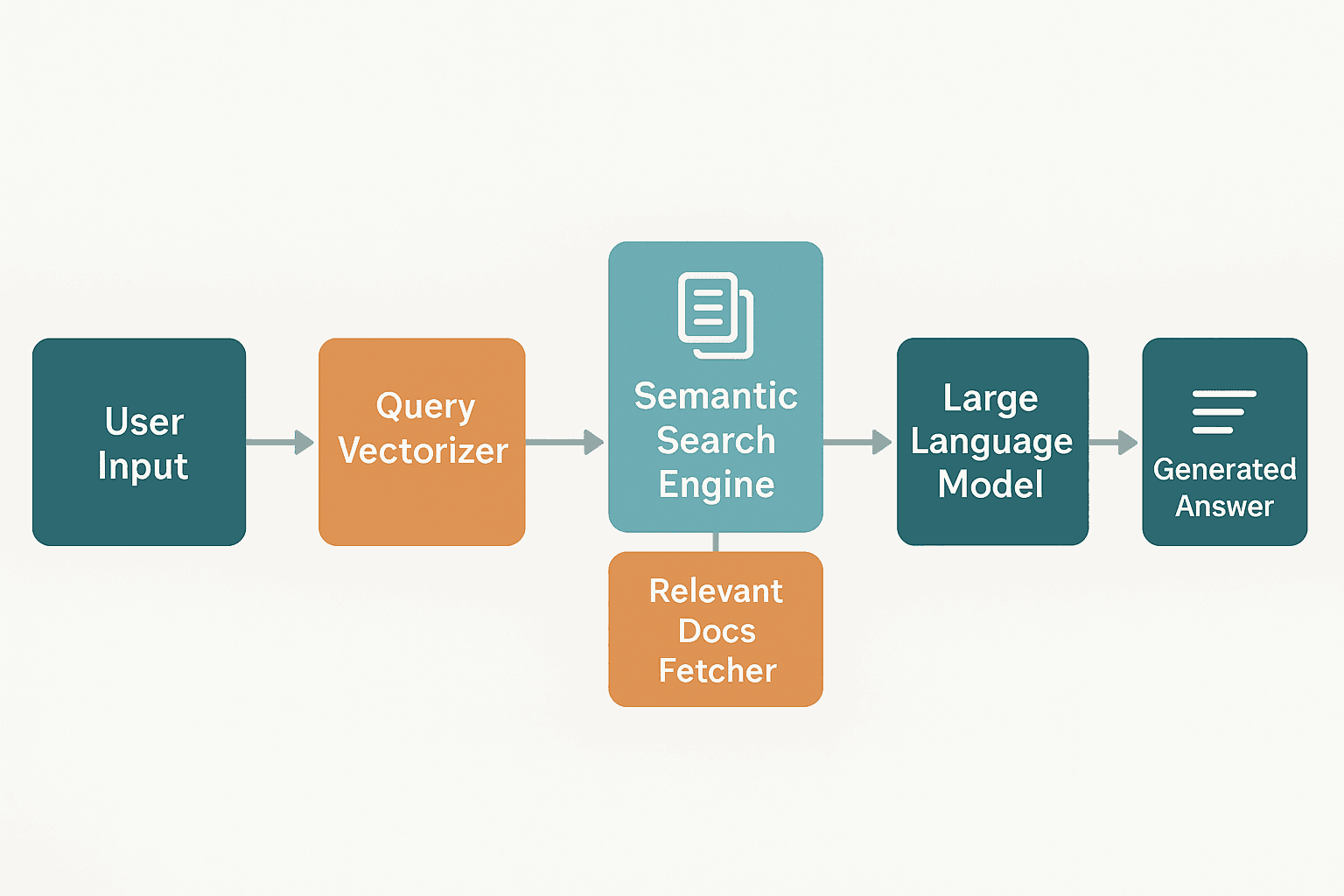
How RAG Improves the Accuracy of LLM Responses
Retrieval-Augmented Generation enhances large language models by tackling their most common shortcomings. Here's how RAG makes LLMs more accurate, trustworthy, and adaptable in real-world applications:
Tackling LLM Limitations
Standard LLMs often "hallucinate", which means they confidently generate incorrect or misleading information. They're also trained on static datasets, which means their knowledge becomes outdated over time. They can’t verify sources or indicate where their answers come from. RAG, along with browser plugins, fixes this by retrieving relevant documents in real time. Using this information, it generates grounded responses. By injecting current, topic-specific knowledge into the generation process, RAG minimizes guesswork and enhances reliability.
Enhancing Accuracy and Trust
When LLMs generate responses based on retrieved documents, users can trace answers back to the real sources. This grounding process not only boosts accuracy but also builds trust. Users are more confident when they know where the information came from and can double-check it. RAG turns LLMs from black boxes into transparent, verifiable tools.
Keeping Models Up to Date Without Re-Training
Keeping an LLM up to date requires expensive, time-consuming retraining. RAG offers a smarter alternative. With RAG, you can connect the model to dynamic external data sources like websites, databases, or company files. This means the model stays current without retraining. Industries like finance, healthcare, and legal, where information changes rapidly, greatly benefit from RAG’s ability to deliver timely, relevant answers without delay.
Developer Control and Customization
RAG gives developers fine-grained control over what data sources the model can access and retrieve from, using techniques like WandB, LoRA, chunking, and attention masking. This ensures that sensitive information is protected and outputs are limited to approved content. RAG achieves this with the help of Role-based Access Control (RBAC) or Attribute-based Access Control (ABAC) at the retrieval level. This makes RAG not just powerful, but also safe and customizable for enterprise use.
Key Use Cases of Retrieval-Augmented Generation in LLMs
RAG unlocks powerful capabilities across industries by enabling LLMs to access domain-specific and accurate information. Below are some key areas where RAG makes a meaningful difference:
Internal Knowledge Search
RAG helps employees quickly find answers from vast internal document repositories, FAQs, or policy manuals. It improves efficiency and reduces knowledge silos. This is ideal for onboarding, operations, and HR support.
Healthcare Assistance
In healthcare, staying current with research, treatment protocols, and medical guidelines is critical. RAG enables LLMs to access updated clinical databases, providing evidence-based responses to support doctors, nurses, and patients.
Customer Support Automation
LLMs powered by RAG can pull answers directly from product manuals, help centers, or ticket history to resolve queries. This reduces repetitive tasks for agents and ensures that customers receive relevant support, depending on their data history.
Software & Code Support
RAG enhances developer productivity by enabling LLMs to fetch solutions from internal codebases, API documentation, or engineering wikis. Whether it’s resolving bugs or generating code snippets, RAG ensures the responses are relevant and practical.
How E2E's TIR Platform Unlocks RAG’s Full Potential for LLMs
E2E Cloud's TIR AI/ML Platform enables easy integration of LLMs using RAG to enhance AI applications:
Enhanced AI Accuracy
TIR's RAG feature, along with APIs or streaming databases, improves model responses, ensuring outputs are both current and precise by integrating real-time, relevant data.
Seamless Data Integration
TIR facilitates effortless connection to multiple data sources, enabling uninterrupted processing and a more comprehensive understanding of user queries.

Enterprise-Grade Security
TIR ensures compliance and safeguards sensitive information with robust security measures, recognizing the importance of data protection.
Scalable & Flexible Architecture
TIR's dynamic and customizable pipeline architectures allow businesses to adapt their AI models in alignment with evolving needs and demands.
Optimized Performance
TIR reduces latency and enhances AI response times, providing users with swift and accurate information by streamlining the retrieval process.
Whether you're building an AI assistant or a domain-specific chatbot, the TIR Platform provides the foundation you need to unlock RAG’s full potential.
FAQs on RAG in LLM
Here are quick answers to some common questions about using Retrieval-Augmented Generation with large language models:
How reliable is RAG currently?
RAG is highly reliable when set up with quality data sources and proper retrieval mechanisms. It significantly reduces hallucinations and boosts accuracy, especially in domain-specific or fast-changing contexts like finance, healthcare, or customer support.
How can I measure the response quality of my RAG?
You can evaluate RAG responses using metrics like relevance, factual accuracy, and source traceability. Human feedback, precision-recall scoring, and benchmarks like EM (Exact Match) or BLEU scores are commonly used for structured assessment.
Is LLM necessary for RAG if we can retrieve an answer from the vector database?
Yes. The vector database handles retrieval, but the LLM is needed to generate natural, coherent, and contextually relevant responses using the retrieved data through Natural Language Processing (NLP). Without the LLM, you’d only get raw snippets, not conversational answers.