Deploying machine learning models is often a complex task involving containerization, DevOps setup, and infrastructure management. TIR Foundation Studio simplifies this process with a no-code deployment interface that allows users to deploy models with just a few clicks.
This guide walks you through the step-by-step process of deploying a fine-tuned model on TIR Foundation Studio, from setting up a repository to accessing the deployed model through an API.
This process is ideal for those seeking fast, scalable Large Language Model (LLM) deployment, inference-as-a-service, and no-code model serving solutions. Each section includes a screenshot placeholder to guide you visually.
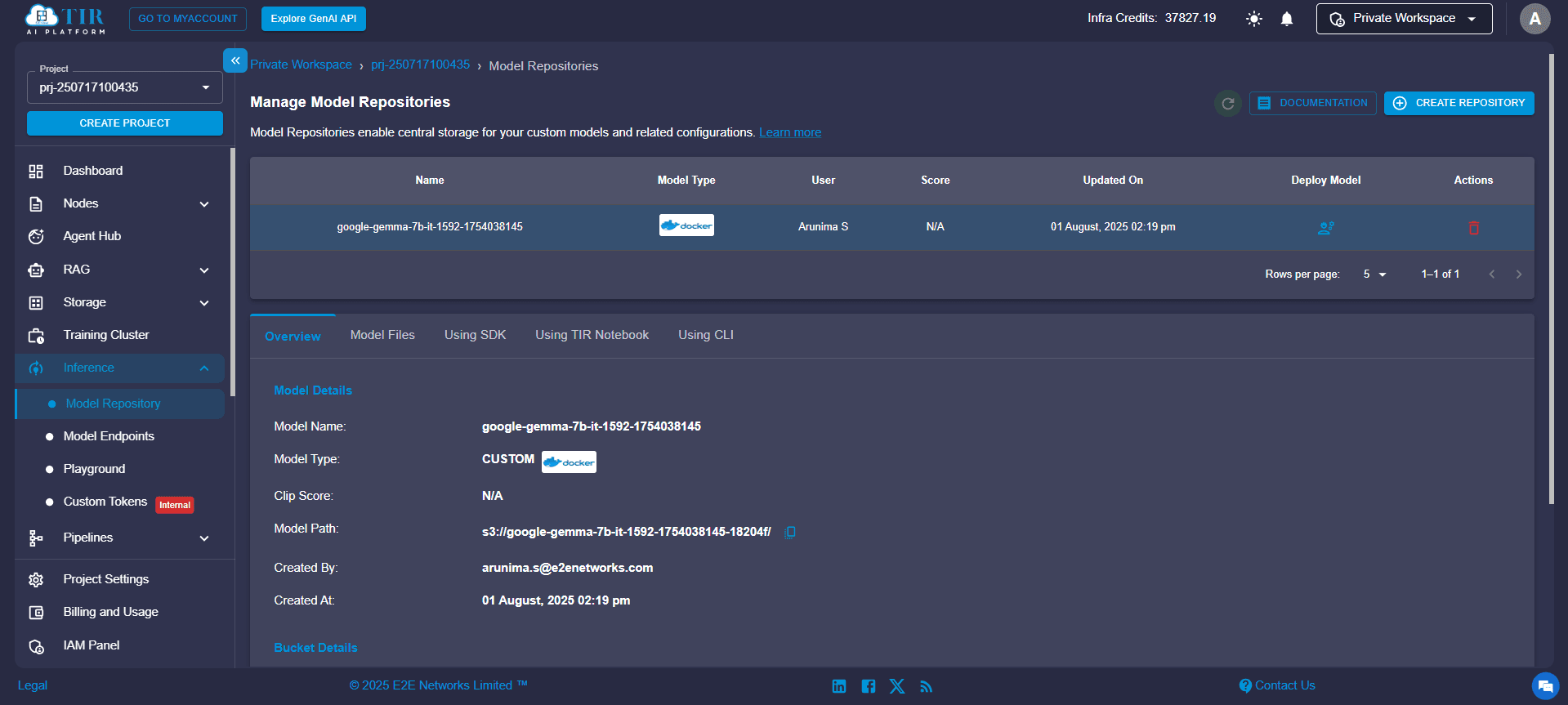
Step 1: Create a Repository
A repository in TIR serves as the storage unit for your model's configuration, metadata, and any associated artifacts. It acts as the root container under which deployments are managed. This is your first step toward bring-your-own-model (BYOM) support.
To begin:
- Navigate to the TIR dashboard.
- Click on “Create Repository”.
- Enter a suitable name and optional description.
Step 2: Click “Deploy Model”
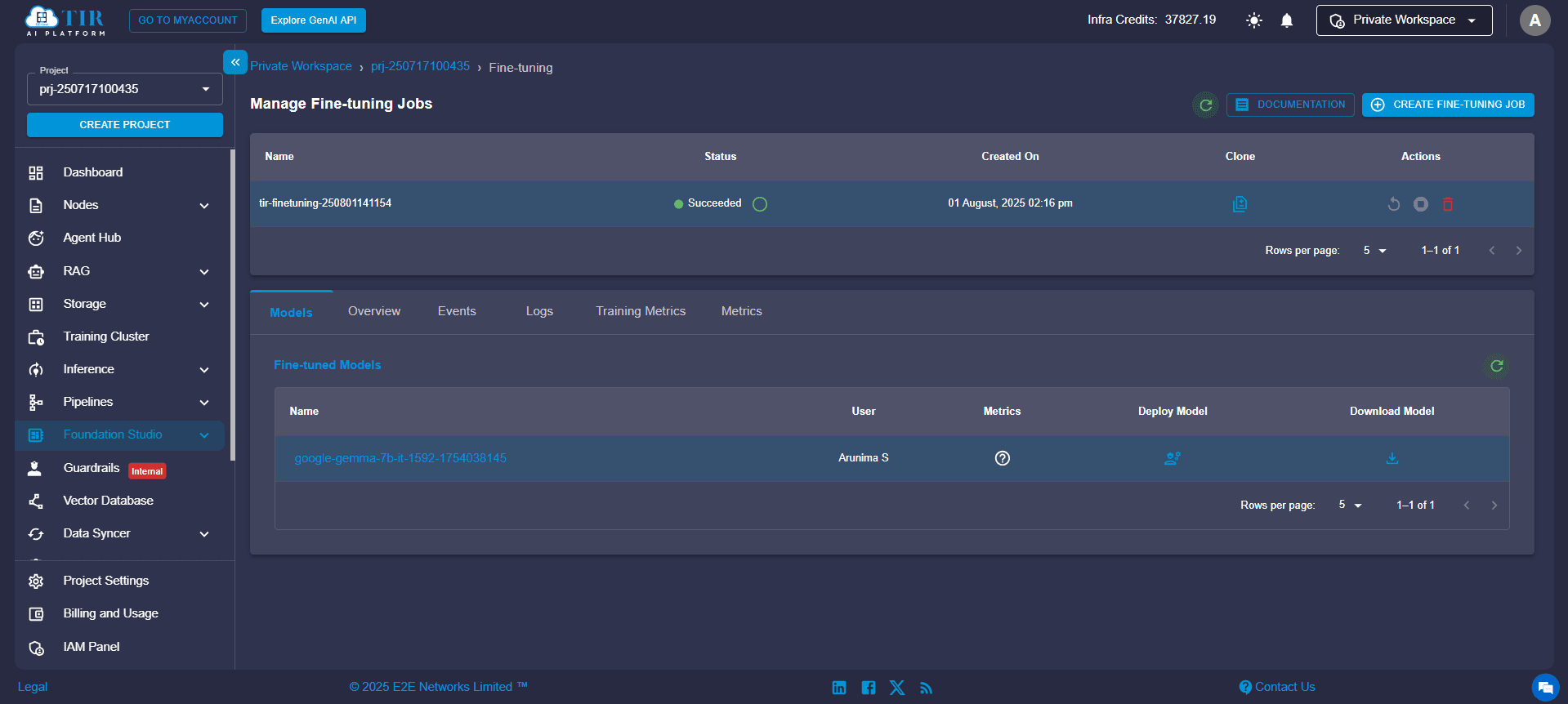
Once your repository is created, go to Foundation Studio and click the “Deploy Model” button to begin the deployment process. This launches a guided configuration wizard that abstracts the complexity of MLOps and offers a low-code/no-code AI deployment experience.
Step 3: Set Endpoint Name
An endpoint is the public or private URL where your model will be hosted for inference. You’ll use this endpoint for serving predictions through the TIR API or Model Playground.
- Choose a unique and descriptive name for your endpoint.
- This name will be used in API calls and testing interfaces.
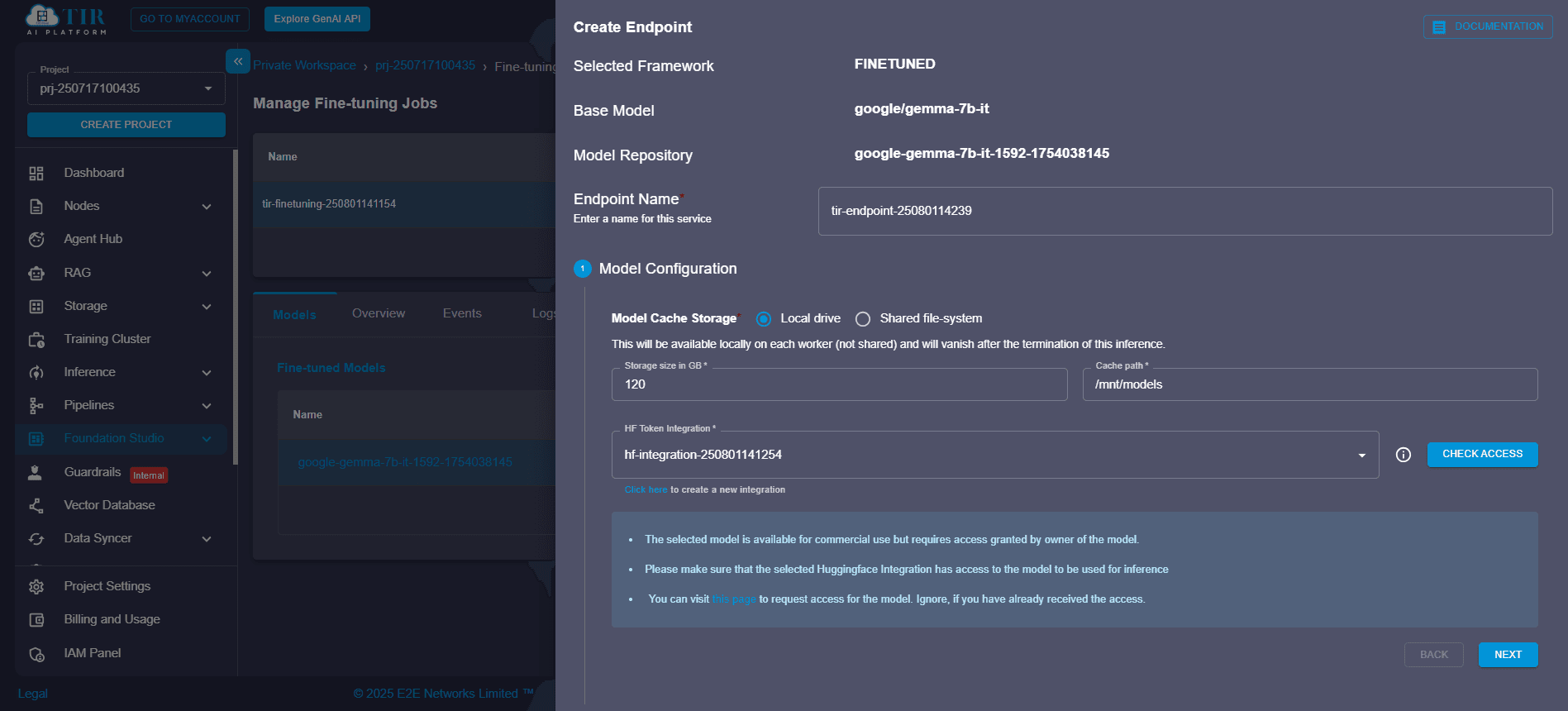
Step 4: Model Configuration
Choose Source
Specify where your fine-tuned model is stored:
- Local Drive: Upload model files from your machine.
- Shared File System (SFS): Select from pre-mounted model directories.
Define Storage Size
Set the disk allocation based on the size of your fine-tuned transformer model, LLM checkpoint, or embeddings.
Set Cache Path
Configure the cache path to manage Hugging Face or PyTorch downloads efficiently. Recommended path: /mnt/model/.cache.
These settings ensure optimal Hugging Face model deployment workflows.
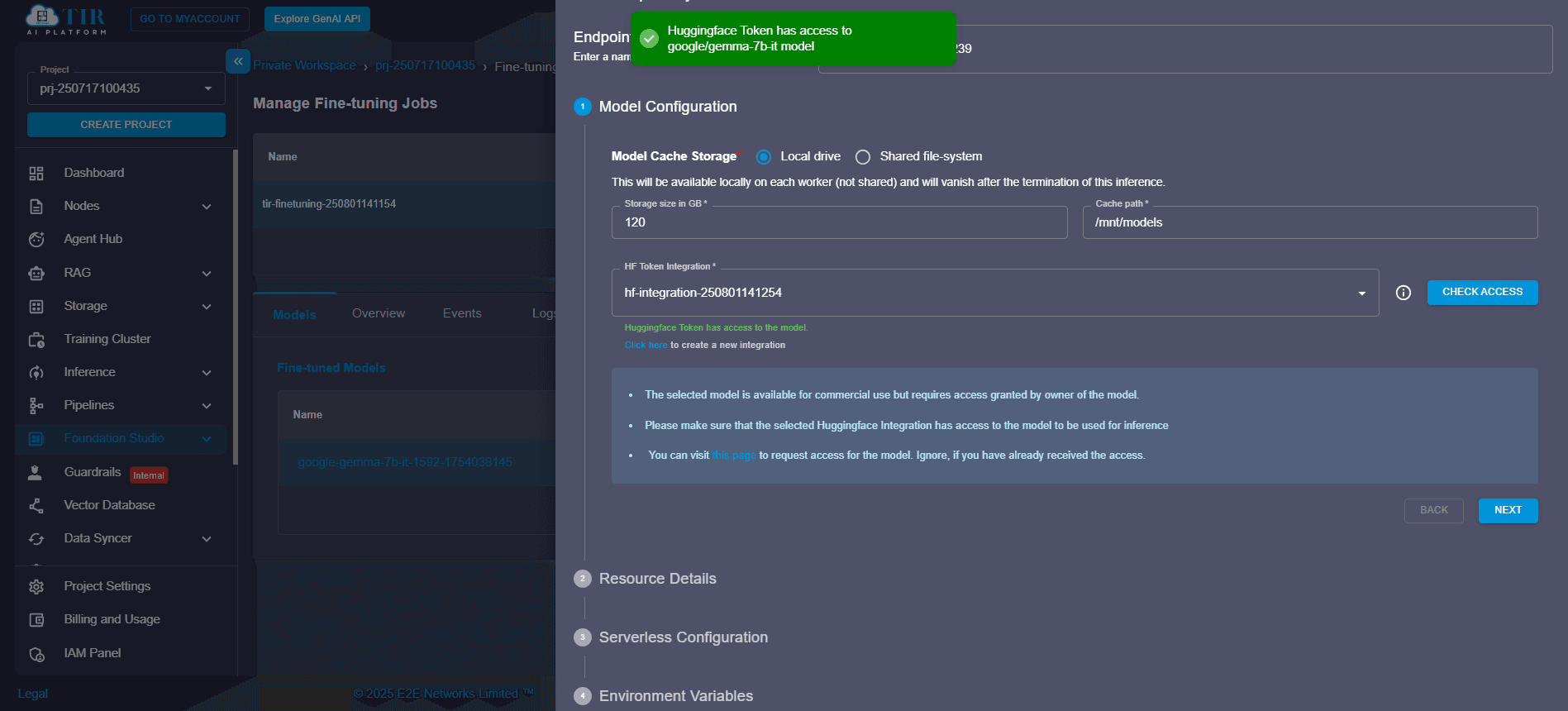
Step 5: Check Access Using Hugging Face Token
To deploy a model from the Hugging Face Hub, authenticate using a valid Hugging Face access token:
- Click “Check Access” to validate your token.
- If needed, generate a new token from the same interface.
This is critical for deploying private LLMs, custom-trained models, or fine-tuned transformers hosted on Hugging Face.
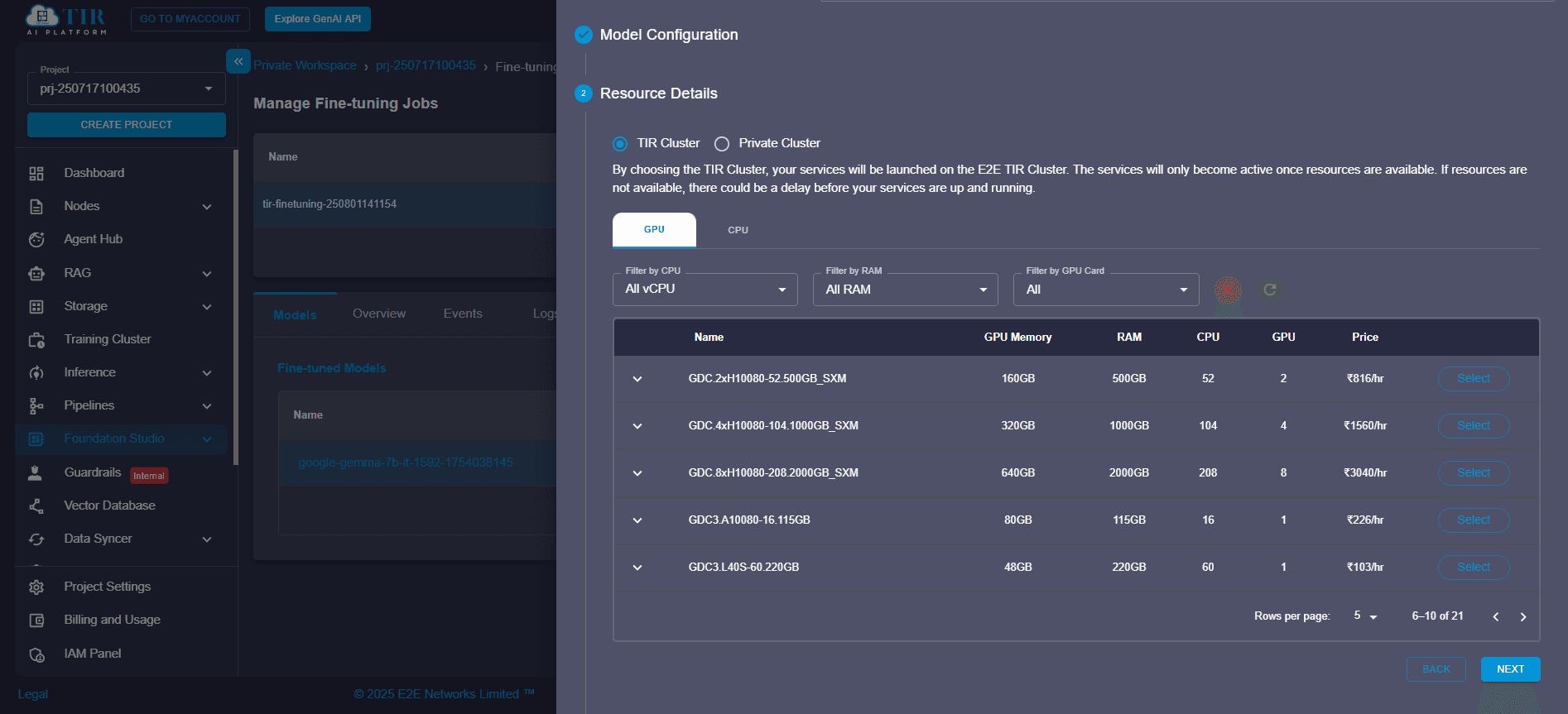
Step 6: Configure Resources
Select Compute Type
Pick the compute infrastructure best suited for your model:
- CPU-only: For lightweight or rule-based models.
- GPU-based: For transformers, diffusion models, and other deep learning models.
Choose Plan
TIR offers resource plans like A100 GPUs with 80GB vRAM, ideal for LLM deployment and multi-modal models.
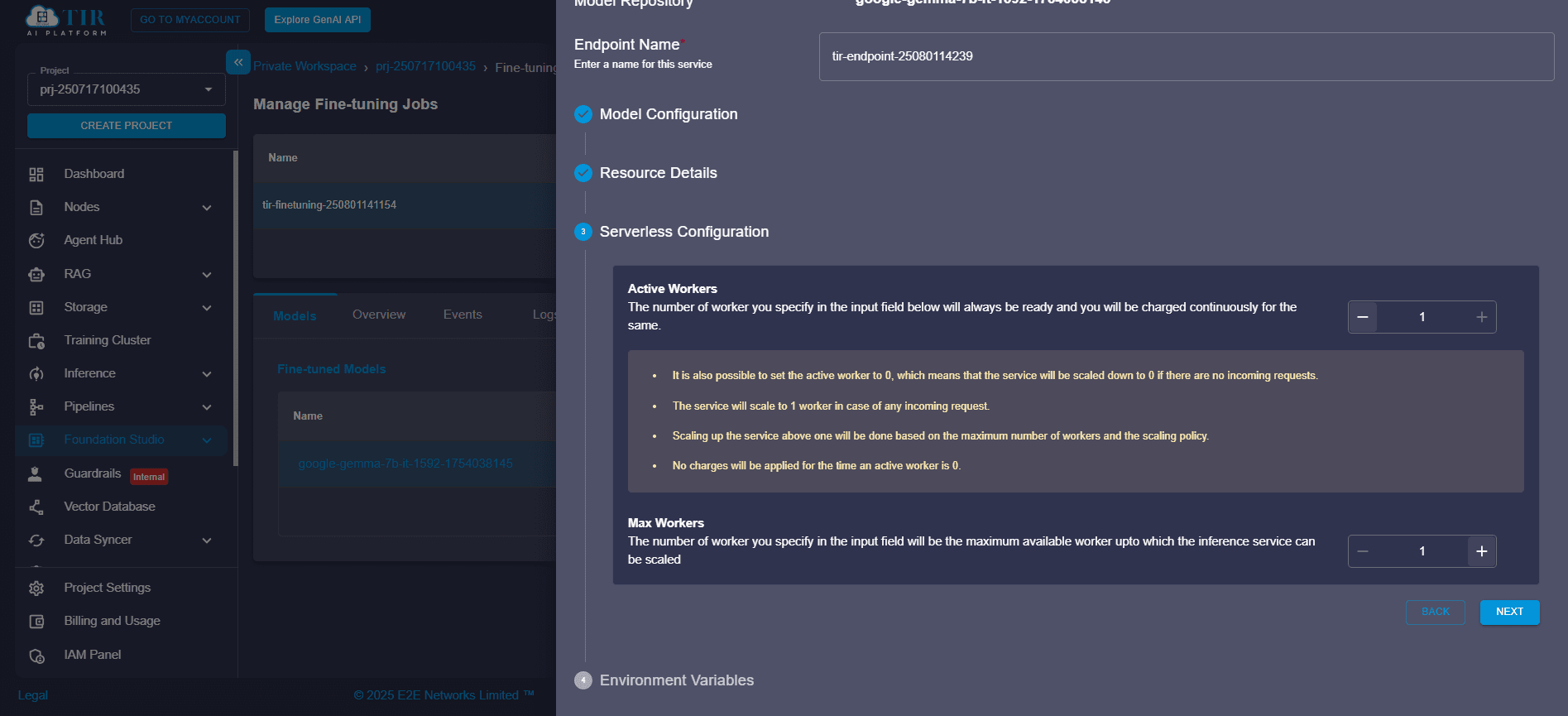
Step 7: Configure Serverless Runtime
TIR supports serverless model serving, meaning your resources scale automatically based on usage.
- Active Workers: Number of always-on instances.
- Maximum Workers: Peak scaling limit under heavy load.
This setup is perfect for production-grade model-as-a-service scenarios.
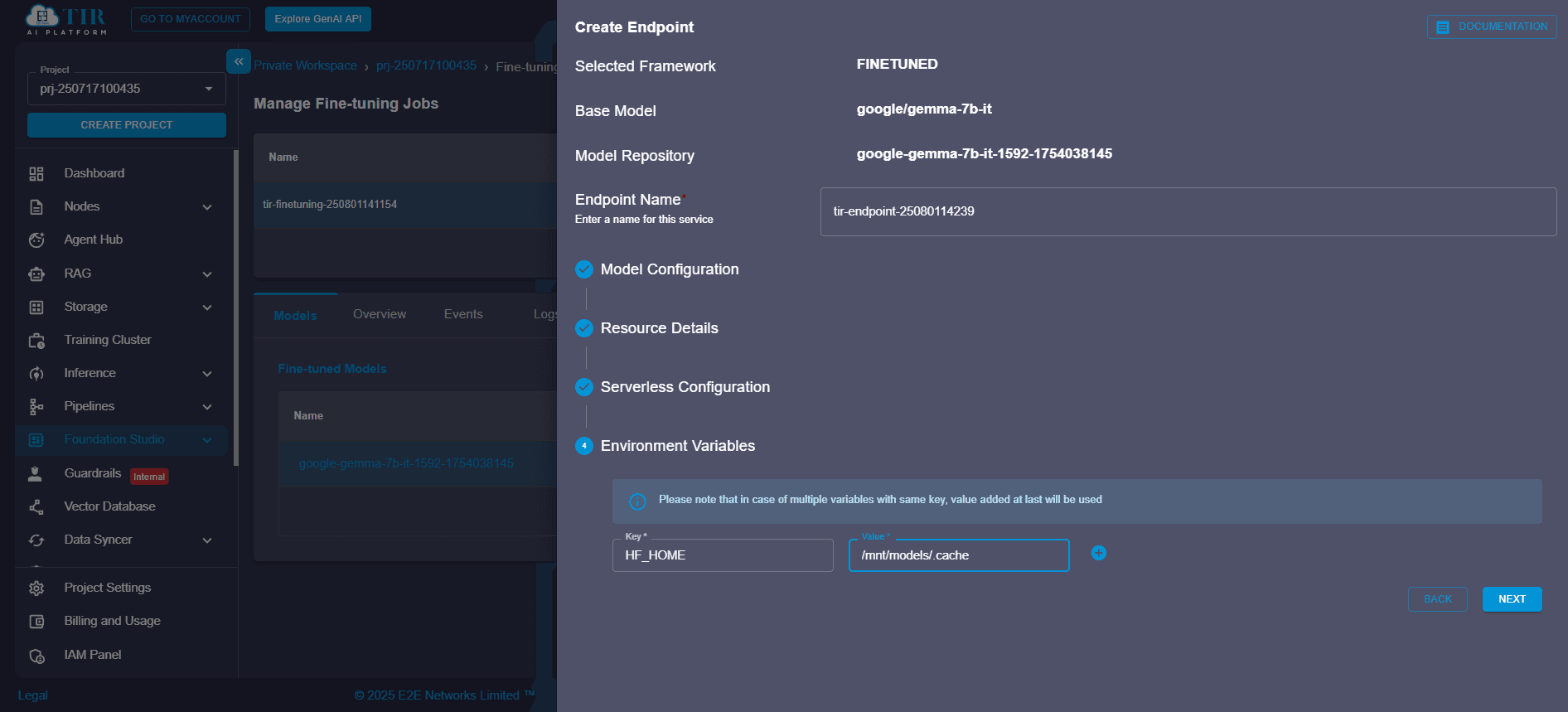
Step 8: Add Environment Variables
Environment variables allow runtime customization without modifying code. Useful keys include:
- HF_HOME: Path where Hugging Face stores model files
- TRANSFORMERS_CACHE: Directory for transformer cache
Note: If multiple variables have the same key, the last one added takes effect.
This is essential for self-hosted LLMs and managing model cache paths during deployment.
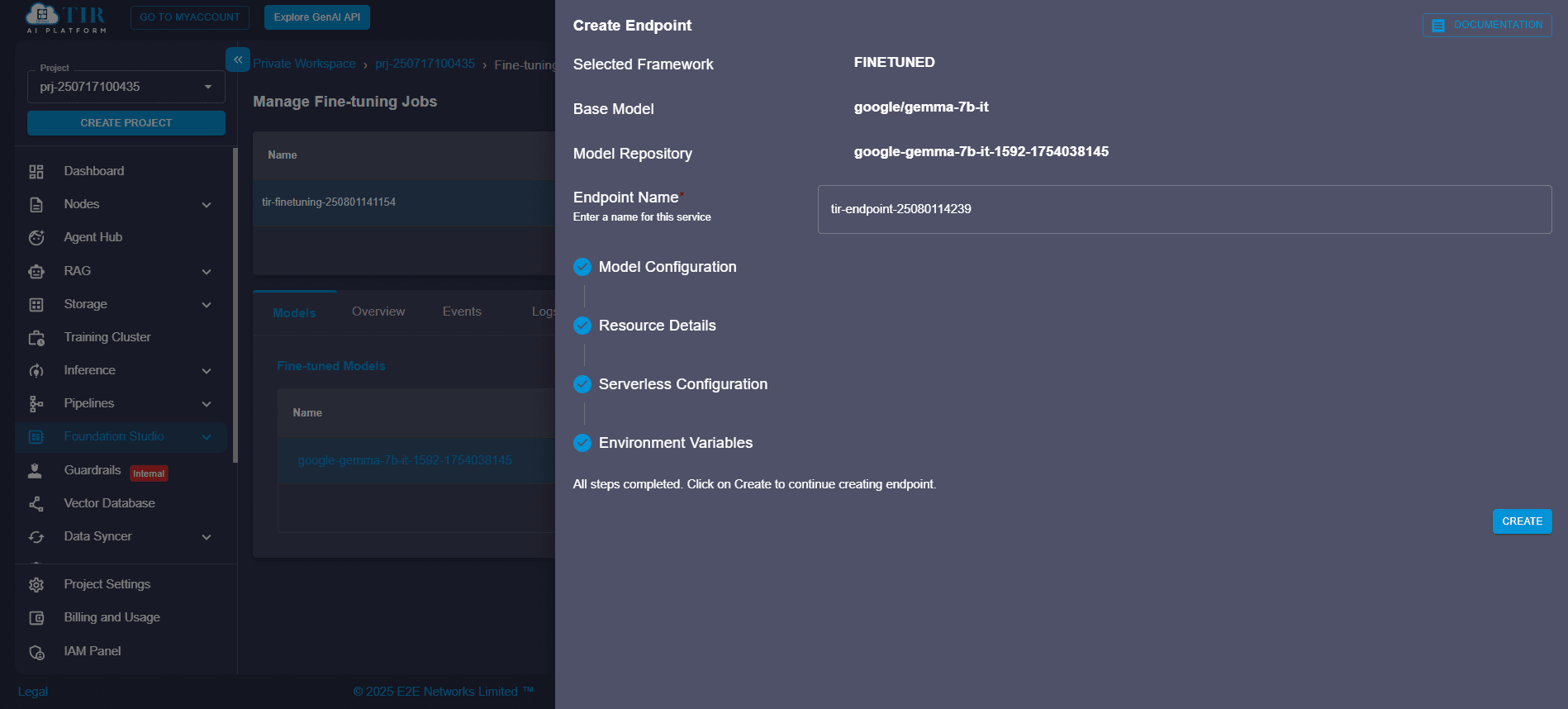
Step 9: Create the Endpoint
Click “Create Endpoint” to finalize deployment. TIR will:
- Instantiate a containerized runtime
- Pull and cache the model weights
- Initialize the inference server
Track real-time:
- Status (starting, running, failed)
- Logs for debugging
- Events to understand runtime behavior
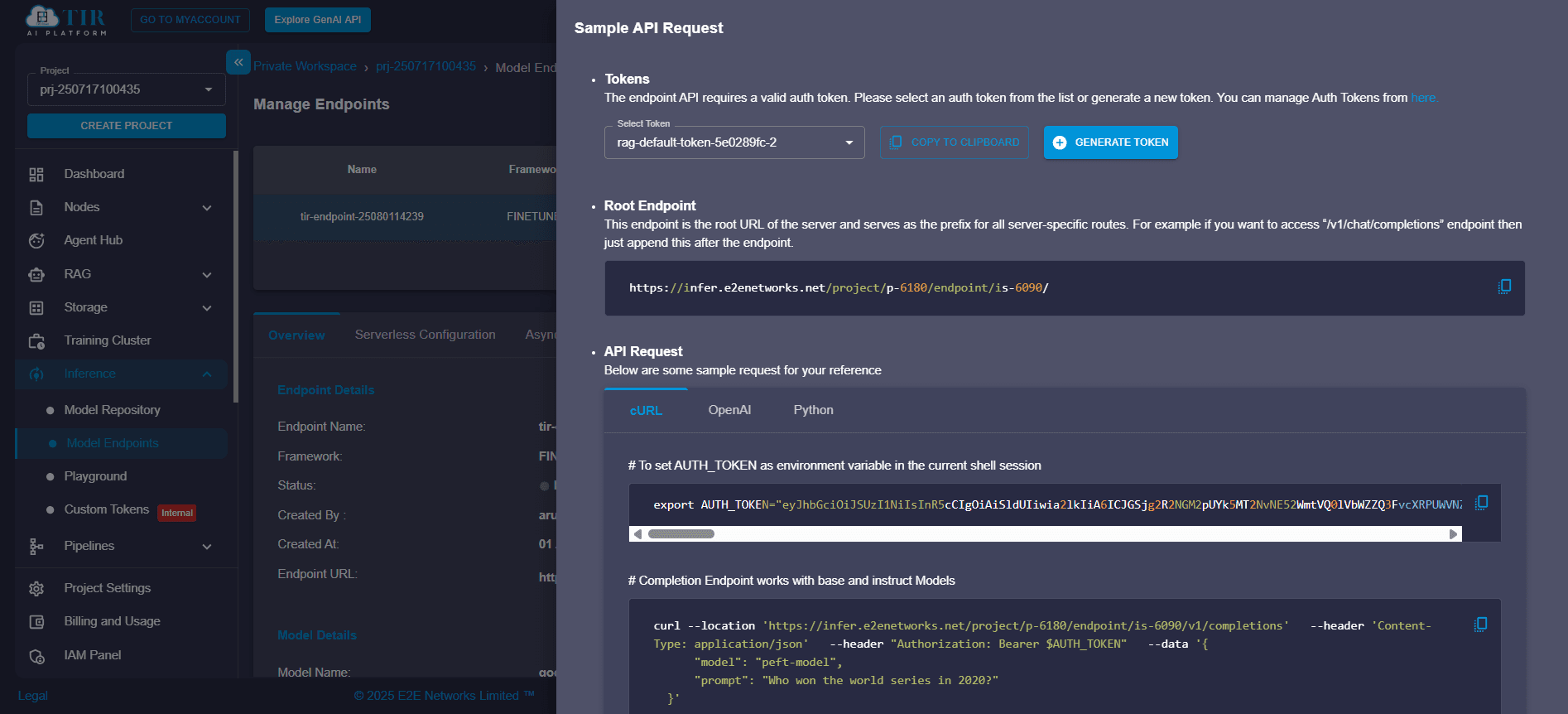
Step 10: Generate API Token and Make Inference Calls
Once validated, switch to the API Request tab to:
- Generate an authentication token
- Access a code snippet (cURL or Python)
- Start production inference workflows
This enables seamless integration with external apps, dashboards, or chatbots.
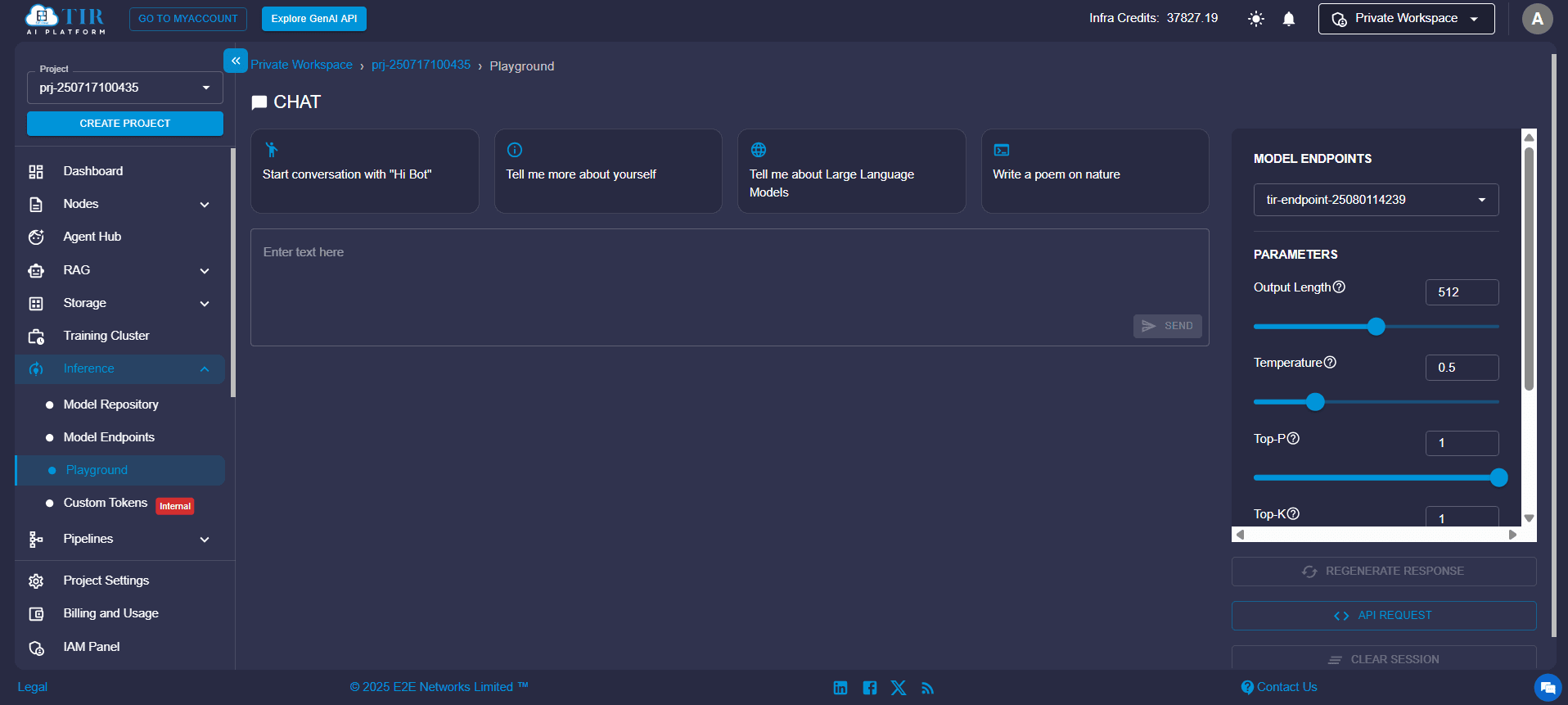
Test the Model in Playground
Use TIR’s built-in Model Playground to test inference before going live:
- Input sample prompts or data
- Review responses without writing any code
Ideal for validating LLMs, fine-tuned QA models, or classification tasks interactively.
Why TIR Makes Model Deployment Effortless
Deploying fine-tuned models shouldn’t require navigating complex DevOps pipelines or managing container orchestration manually. With TIR’s no-code deployment interface, you can go from model checkpoint to scalable endpoint in minutes.
TIR is purpose-built for:
- Hosting fine-tuned LLMs and transformer models from local drives or shared file systems.
- Avoiding infrastructure headaches with no Dockerfiles or YAMLs required.
- Running models on cost-effective GPU-backed serverless instances that scale with demand.
- Serving models interactively via a built-in Playground or securely via token-authenticated APIs.
Whether you're a data scientist experimenting with prototypes, an ML engineer deploying production workloads, or a startup founder shipping a feature powered by AI, TIR streamlines the entire lifecycle of getting your model online.
Real-World Applications
The ability to deploy fine-tuned models without writing backend code opens up a variety of impactful use cases:
Customer Support Chatbots
Fine-tune a language model on your company’s support documentation and deploy it on TIR to instantly provide API-accessible customer assistance, perfect for embedding into chat widgets or apps.
Healthcare NLP Tools
Researchers can serve clinical QA models or summarization tools trained on medical literature, enabling fast access to insights without managing infrastructure or exposing sensitive data to external APIs.
SaaS Model-as-a-Service
Startups building AI-powered SaaS tools, such as document analyzers, data extractors, or content summarizers, can deploy their models using TIR’s scalable backend and focus on frontend UX.
Enterprise AI Workflows
Deploying internal, domain-specific LLMs on TIR lets organizations keep model inference private, cost-efficient, and compliant with data governance policies without external hosting.
Ready to Deploy Your First AI Model?
Bringing your own fine-tuned model (BYOM) to life no longer requires complex DevOps pipelines, custom APIs, or infrastructure headaches. With TIR’s no-code deployment interface, you can move from a local model checkpoint to a fully scalable, production-ready endpoint in just a few clicks.
Whether you're building custom LLMs, transformer-based NLP tools, or domain-specific AI models, TIR abstracts away the operational complexity so you can focus on building, testing, and iterating faster.
Get started with TIR Foundation Studio today and experience just how fast BYOM deployment can be no-code, no infrastructure setup, and no limits to what you can build.









