Image-to-text tools have come a long way. Most can extract text from documents like invoices, receipts, or reports using Optical Character Recognition (OCR). But in many cases, simply extracting text isn’t enough.
What if you could go a step further, not only read the text in an image, but also ask questions about it, store it for future queries, and get meaningful answers?
That’s the goal of this project. It combines image understanding, text embeddings, and semantic search to let you upload an image, extract the content, index it, and query it later using natural language.
This blog walks you through building a vision-aware, memory-enabled AI query system using:
- Meta’s Llama-3.2 Vision-Instruct
- Sentence Transformer for embeddings
- Qdrant for semantic vector search
- Gradio for an interactive frontend
- TIR GPU Platform for scalable deployment
Why Vision Model Based Bots Over OCRs
There are already tools that can extract text from images. But most of them:
- Don’t retain memory across multiple files
- Can’t answer detailed questions from stored content
- Work only on one image at a time
This system is designed for scenarios where you need to:
- Upload many documents over time
- Search through them using meaning, not keywords
- Get contextual answers across multiple image-based inputs
What Qdrant Adds
Qdrant adds a layer of semantic indexing and retrieval to your Llama 3.2 Vision pipeline. Instead of just processing images one by one, Qdrant allows you to persistently store the extracted content from each image in a vector database, where each entry is represented by its semantic meaning. This enables fast and intelligent search across many image-derived texts using vector similarity.
For instance, even if a user's query doesn't use the exact words from the image content, Qdrant can still retrieve the most relevant matches based on meaning. This is especially useful in use cases like invoice analysis, document summarization, or visual QA, where hundreds or thousands of documents may be uploaded, and users want answers without manually reading through them.
It also enables real-time retrieval, batch indexing, and long-term reuse of previously processed data, making the system production-ready and scalable.
Real-World Applications
| Domain | Challenge | What This System Enables |
|---|---|---|
| Invoicing | Finding the tax amount from past scanned invoices | Ask: "Which invoices had IGST above ₹5000?" |
| Healthcare | Extracting patient insights from reports and scans | Ask: "What diagnosis did Patient X receive?" |
| Compliance | Searching visual contracts for legal clauses | Ask: "Find NDAs mentioning Singapore arbitration." |
| Education | Scanning handwritten assignments or forms | Ask: "Who solved Question 3 incorrectly?" |
How It Works
Here’s the basic idea:
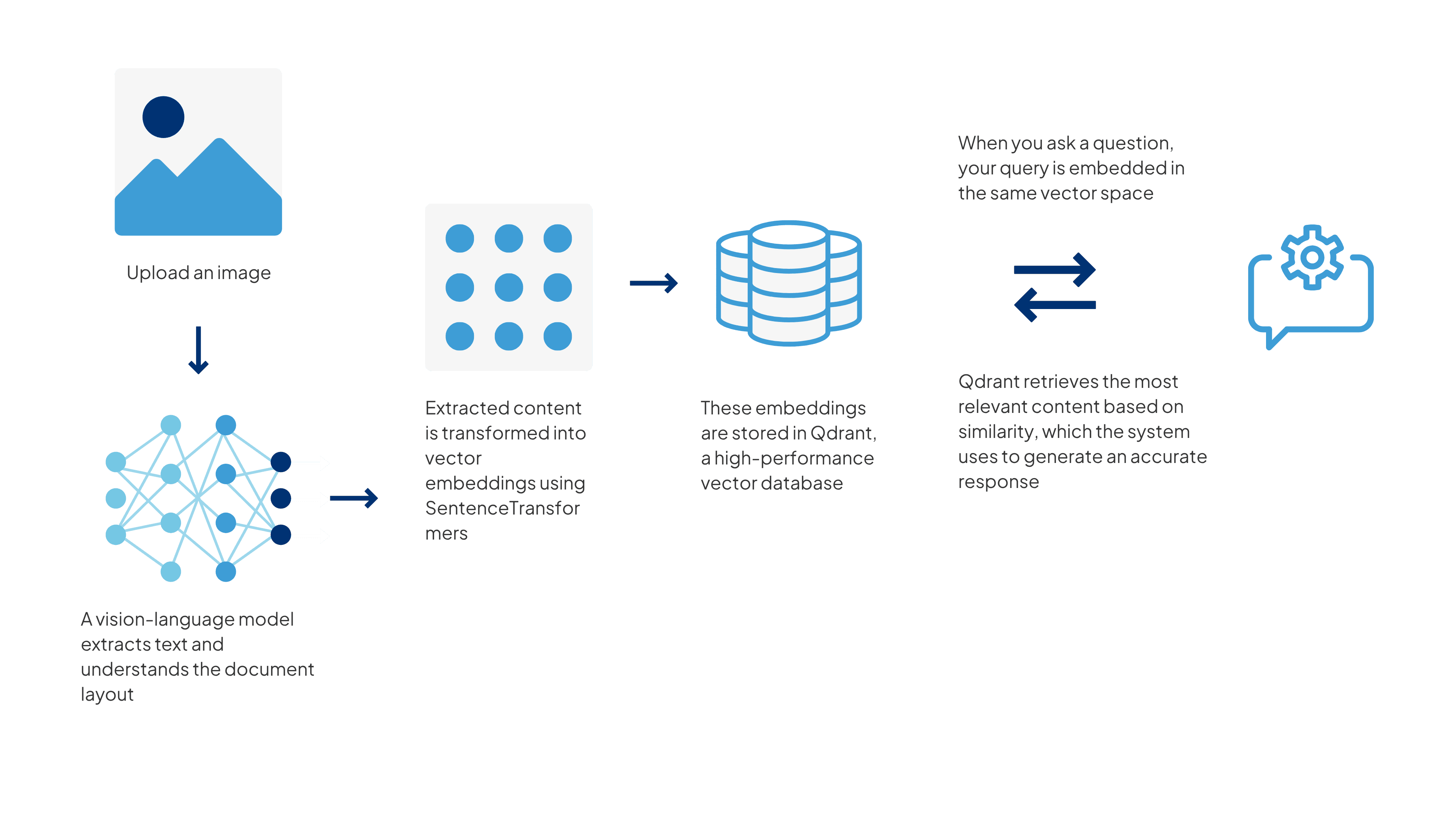
This lets you work with multiple documents over time and still get meaningful answers from them.
Running the Workflow on TIR
This project was built and tested on the E2E Cloud’s TIR platform, using a GPU-backed instance tailored for deep learning workloads. The environment came preloaded with Python 3.10, CUDA 12.4, and Transformers v4.51.3, all running on Ubuntu 22.04, making it a solid fit for deploying large vision-language models like Llama 3.2.
Here’s a quick look at the instance specs:
| Resource | Specification |
|---|---|
| Platform | E2E TIR |
| Node | A100 GPU |
| RAM | 32+ GB |
| vCPUs | 8+ |
| Storage | 10+ GB |
| Docker Image | e2e/tir-transformer-py310:v1 |
This setup provided both the flexibility and compute needed to handle multi-modal processing and vector indexing with ease.
Code Walkthrough
Follow these coding steps in the Jupyter Notebook within your launched instance.
Libraries You'll Need
Install these Python packages in your environment:
pip install torch torchvision torchaudio
pip install transformers sentence-transformers
pip install qdrant-client gradio pillow
pip install huggingface-hub
Log in to Hugging Face to access the vision model:
from huggingface_hub import login
login(token="your_hf_token_id")
1. Load the Models and Services
import torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id, torch_dtype=torch.bfloat16, device_map="auto"
)
processor = AutoProcessor.from_pretrained(model_id)
2. Set Up the Qdrant Collection
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from sentence_transformers import SentenceTransformer
import uuid
# Initialize Qdrant (local or cloud)
qdrant = QdrantClient(path="qdrant_data") # use host/api_key for Qdrant Cloud
COLLECTION_NAME = "vision-index"
# Create collection if not exists
if not qdrant.collection_exists(COLLECTION_NAME):
qdrant.recreate_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=384, distance=Distance.COSINE)
)
# Load embedding model
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
3. Retrieve Context and Generate Answer
def vision_rag_index(images, query):
log = ""
extracted_texts = []
for img in images:
log += f"Processing image: {img.name}\n"
image = Image.open(img.name).convert("RGB")
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Describe the image"}
]}
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256)
response = processor.decode(outputs[0], skip_special_tokens=True)
extracted_texts.append(response)
4. Embed and Store Text in Qdrant
# Index to Qdrant
vector = embedding_model.encode(response).tolist()
qdrant.upsert(
collection_name=COLLECTION_NAME,
points=[PointStruct(id=str(uuid.uuid4()), vector=vector, payload={"text": response})]
)
log += f"Indexed: {response}\n"
# Now use the query to search in Qdrant
query_vector = embedding_model.encode(query).tolist()
hits = qdrant.search(
collection_name=COLLECTION_NAME,
query_vector=query_vector,
limit=3
)
results = "\n".join([f"Score: {hit.score:.2f}\nText: {hit.payload['text']}" for hit in hits])
return log + "\n\n Search Results:\n" + results
5. Try It Out with a Web UI
with gr.Blocks(title="Llama 3.2 Vision RAG + Qdrant") as demo:
gr.Markdown("## Upload images and ask questions")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(file_types=["image"], file_count="multiple", label="Upload Images")
query = gr.Textbox(label="Query", placeholder="e.g. What is the total amount billed?")
btn = gr.Button("Submit")
with gr.Column(scale=2):
output_box = gr.Textbox(label="Output", lines=20)
btn.click(fn=vision_rag_index, inputs=[file_input, query], outputs=output_box)
demo.launch(share=True)
This will open a simple Gradio interface where you can upload an image and ask a question.
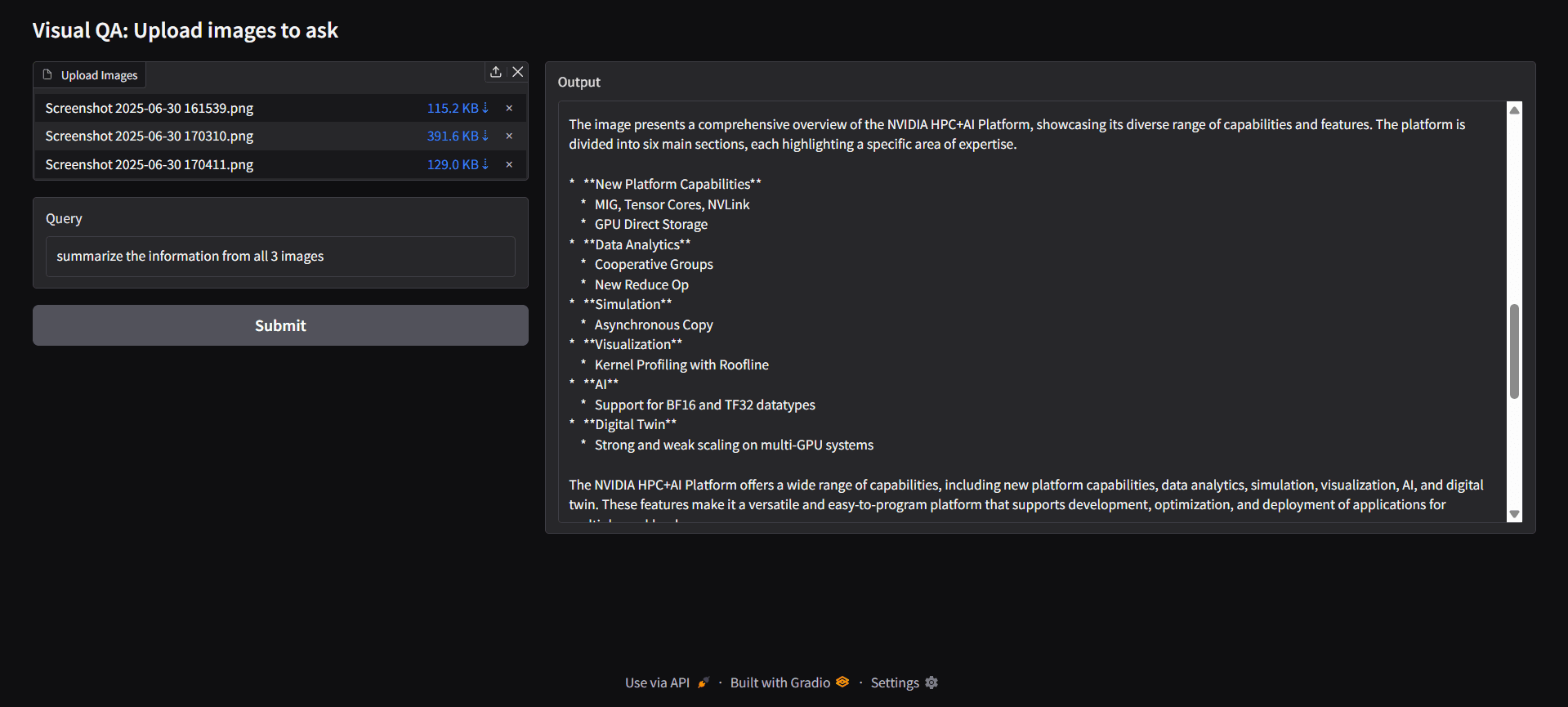
When you upload an image and type a query, the system will:
- Extract text from the image
- Search the stored embeddings in Qdrant for relevant content
- Generate an answer using the retrieved context
This makes it useful for cases where you want to build a memory or search engine for scanned documents.
Common Issues and Fixes
| Problem | Reason | How to Fix |
|---|---|---|
| CUDA OOM | Model or image size is too large | Try smaller images or use a bigger GPU |
| Qdrant not saving data | In-memory mode doesn't persist | Use a cloud-hosted Qdrant URL |
| Hugging Face token error | Not logged in | Use huggingface-cli login or login(token=...) |
| Model loading is slow | Model size is large | Pre-download or use a smaller variant |
Integration Ideas
This system can be integrated into a variety of enterprise tools and workflows to add intelligent document understanding capabilities. For example, it can enhance invoice management dashboards by automatically extracting and organizing billing information from uploaded invoices.
In legal or compliance document systems, it can help process scanned contracts or regulatory paperwork, making them searchable and interactive. Internal knowledge bases can benefit by allowing employees to convert scanned PDFs, invoices, and receipts into searchable, editable text, while healthcare reporting tools can use it to extract structured data from lab reports or prescriptions.
The modular nature of the system, comprising image upload, vision-language text extraction, embedding-based indexing, and intelligent querying, makes it highly adaptable. Each component can be reused or replaced depending on the specific application requirements, ensuring flexibility and long-term scalability.
What to Improve
- Connect to a persistent Qdrant instance
- Add support for batch uploads
- Use an OCR fallback for low-quality images
- Train custom embeddings for your industry
- Add metadata or tags to organize indexed data
Deploying Vision Models Through TIR
This project shows how you can build a useful, production-ready image-to-query system using open-source tools and cloud infrastructure. Unlike a free OCR to Word converter, it lets you store, search, and reason over image content in a meaningful way.
If you're working with scanned documents regularly, whether invoices, reports, contracts, or forms, this kind of system can help you automate tasks and reduce manual searching.
Start building with TIR Foundation Studio today!