Introduction
In the digital age, the sheer volume of academic documents available online has grown exponentially. Researchers, students, and scholars often find themselves navigating vast collections of PDFs, struggling to extract information efficiently. That's where Nougat, an innovative system developed by Meta, comes into play. Nougat leverages the power of Neural Optical Understanding to revolutionize the way we interact with academic documents.
Understanding Nougat
Nougat is not your typical document processing tool. It's a sophisticated system built upon the foundation of cutting-edge machine learning techniques, particularly the Document Understanding Transformer (Donut) architecture. Donut combines the strengths of neural networks and transformers to achieve remarkable results in parsing academic documents.
Key Features of Nougat
- Multi-Modal Understanding: Nougat goes beyond traditional text extraction by integrating visual content analysis. It can recognize and interpret not only text but also images, equations, and tables within academic papers.
- Extensive Training Data: To train Nougat effectively, the Meta team compiled a massive dataset of over 8 million articles from sources like arXiv, PubMed Central, and industry documents libraries. This extensive training data empowers Nougat to handle a wide range of academic documents.
- Flexible Output: Nougat outputs the information it extracts from PDFs into a Multi-Markdown file format. This versatile output can be easily integrated into various research workflows and platforms.
Using Nougat
Getting started with Nougat is straightforward, thanks to its user-friendly interface. Researchers and academics can apply Nougat's Optical Character Recognition (OCR) capabilities on their academic documents, enabling them to extract, understand, and work with the content more effectively.
- Batch Processing: Nougat supports batch processing, making it convenient to analyze multiple documents simultaneously. This feature is particularly useful for researchers working with large datasets.
- Image and Text Integration: Nougat seamlessly integrates text and visual content, making it a valuable tool for disciplines where equations, graphs, and images play a crucial role.
- Latex Compatibility: For those in the academic community using LaTeX for document preparation, Nougat's Multi-Markdown output is compatible with LaTeX, ensuring smooth integration into research papers and publications.
Impact on Academic Research
Nougat has the potential to significantly impact academic research in several ways:
- Time Efficiency: By automating the process of content extraction and understanding, Nougat frees up researchers' time, allowing them to focus on higher-level analysis and interpretation.
- Interdisciplinary Research: Nougat's ability to handle both text and visual content encourages interdisciplinary research, where collaboration across diverse fields becomes more accessible.
- Accessibility: The easy-to-use interface of Nougat makes academic documents more accessible to a broader audience, including students, researchers, and educators.
Nougat Workflow
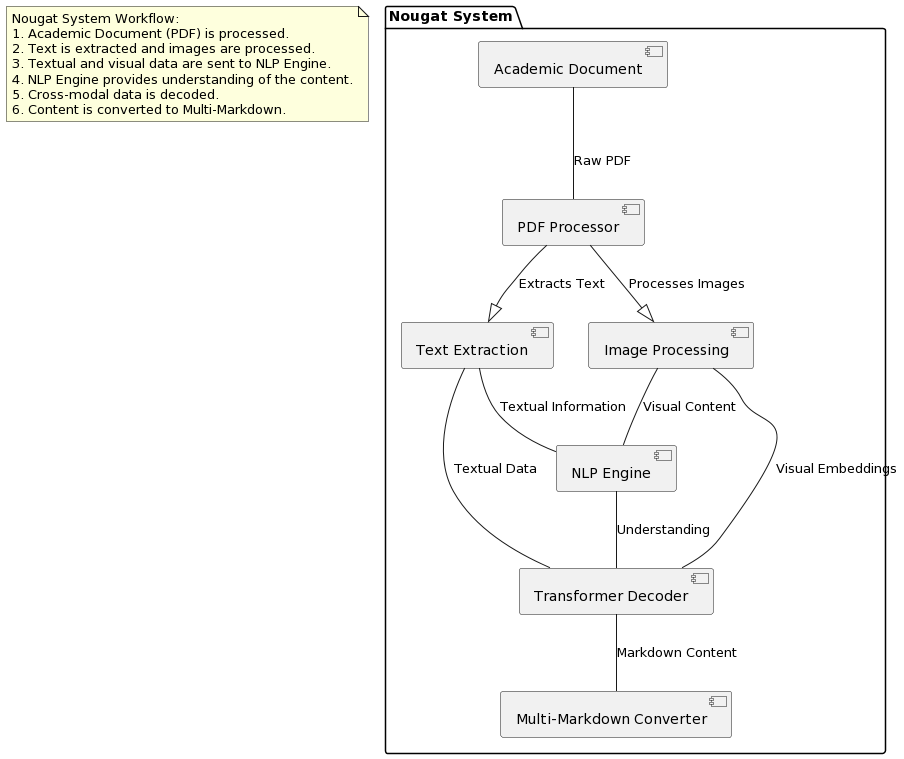
This architectural diagram represents the following components and their interactions:
- Academic Document: Represents the input academic paper in PDF format.
- PDF Processor: This component handles the initial processing of the PDF document, including text extraction and image processing.
- NLP Engine: Stands for Natural Language Processing Engine, responsible for understanding and extracting textual information from the academic document.
- Visual Encoder: Handles the visual content of the document, such as images and equations. It provides image embeddings for further processing.
- Transformer Decoder: Utilizes the Transformer architecture to decode both text and visual information, facilitating a cross-modal understanding of the document.
- Multi-Markdown Converter: Converts the decoded content into multi-markdown format, making it suitable for various applications, including rendering in markdown or LaTeX.
This diagram offers a high-level view of how Nougat processes academic documents, incorporating both textual and visual elements to achieve optical understanding.
Please note that this is a simplified representation, and the actual Nougat architecture may involve more complex components and interactions. The diagram can be further extended to include details specific to the Nougat system's implementation and additional components
Flow of Image Augmentation in Nougat

The above given flow shows the different image augmentation methods used during training the model. A more detailed flow is shown in this paper with a sample document example.
Hands-On Examples on Using Nougat
- Tutorial 1
Introduction
This tutorial explores the practical application of Meta's Nougat model for Optical Character Recognition (OCR) on academic and scientific papers. Nougat is an advanced neural network model tailored to efficiently parse PDF documents, extract text, mathematical equations, and tables. This comprehensive guide will walk you through essential aspects of using Nougat, from initial setup to OCR processes, batch processing, and additional learning resources.
Table of Contents
- Overview of Nougat
- Environment Setup
- OCR of PDFs
- Natively Digital PDFs
- Scanned PDFs
- Batch Processing
- OCR of Natively Digital PDFs: Unveiling Precision in Equation Recognition while comparing with LaTex
1. Overview of Nougat
Nougat is an encoder-decoder Transformer model based on the Document Understanding Transformer (Donut) architecture. It is specifically designed for handling complex academic documents. Key functionalities of Nougat include:
- Parsing PDF documents.
- Extracting textual content, mathematical equations, and tabular data.
- Utilizing a visual encoder for image processing.
- Decoding content into token sequences through a Transformer decoder.
The model's extensive training on a diverse dataset of over 8 million articles from sources like Archive, PubMed Central, and the Industry Documents Library ensures its adaptability to various academic documents.
2. Environment Setup
Before diving into Nougat's OCR capabilities, it's crucial to set up the environment for smooth execution. Follow these steps:
- Configure the runtime environment to use a GPU.
- Install the necessary modules, including Nougat, IPython, and Os.
from IPython import display
import os
!pip install git+https://github.com/facebookresearch/nougat
display.clear_output()
For getting all the commands and information from the command line, you can refer to the below shown image:
!nougat -h
The output after running the command is:

3. OCR of PDFs
Nougat excels in OCR processes for academic documents, whether they are natively digital PDFs or scanned documents.
3.1. OCR of Natively Digital PDFs
Natively digital PDFs are those already in digital format, simplifying the OCR process:
- Download the target PDF using the curl command or any preferred method.
- Execute Nougat to OCR the PDF and save the output in multi-markdown format.
- Display the extracted content using markdown or render it in LaTeX, e.g., with Overleaf for further formatting.
- Steps in code are as follows:
!curl -o quantum_physics.pdf https://www.sydney.edu.au/science/chemistry/~mjtj/CHEM3117/Resources/postulates.pdf
!nougat --markdown pdf '/content/quantum_physics.pdf' --out 'physics'
Please note: The below shown command is used to view a LaTex formatted file.
display.Latex('/content/physics/quantum_physics.mmd')
3.2. OCR of Scanned PDFs
Scanned PDFs are essentially images of printed or handwritten documents, requiring OCR for text extraction:
- Download the scanned PDF using curl or a suitable method.
- Employ Nougat to perform OCR on the scanned document.
- Post-processing may be necessary for formatting equations and titles when rendering in LaTeX or other tools.
- Steps in code are as follows:
!curl -o fundamental_quantum_equations.pdf https://www.informationphilosopher.com/solutions/scientists/dirac/Fund_QM_1925.pdf
!nougat --markdown pdf '/content/fundamental_quantum_equations.pdf' --out 'physics'
Please note: The below shown command is used to view a LaTex formatted file on E2E itself.
display.Latex('/content/physics/fundamental_quantum_equations.mmd')
4. Batch Processing
Nougat facilitates the efficient processing of multiple PDFs simultaneously, enhancing productivity. Here's how to batch process PDFs:
- Create a directory to store the PDFs intended for processing.
- Iterate through the PDFs in the directory using Python's os module.
- Apply Nougat to each PDF in the batch, saving the results in multi-markdown format.
- Steps in code are as follows:
!mkdir pdfs
!curl -o pdfs/lec_1.pdf https://ocw.mit.edu/courses/8-04-quantum-physics-i-spring-2016/7f930e013cef9cd7dec5aa88baa83f0a_MIT8_04S16_LecNotes1.pdf -o pdfs/lec_2.pdf https://ocw.mit.edu/courses/8-04-quantum-physics-i-spring-2016/afaef4b8271759d352ac75c4e85eaee6_MIT8_04S16_LecNotes2.pdf
!curl -o pdfs/lec_3.pdf https://ocw.mit.edu/courses/8-04-quantum-physics-i-spring-2016/f928b8dce3d6a218fddda9617c5eb4f2_MIT8_04S16_LecNotes3.pdf -o pdfs/lec_4.pdf https://ocw.mit.edu/courses/8-04-quantum-physics-i-spring-2016/0c07cbdc9c352c39eb9539b31ded90d7_MIT8_04S16_LecNotes4.pdf
nougat_cmd = "nougat --markdown --out 'batch_directory'"
pdf_path = '/content/pdfs'
for pdf in os.listdir(pdf_path):
os.system(f"{nougat_cmd} pdf /content/pdfs/{pdf}")
Please note: The below shown command is used to view the markdown file in the colab itself.
display.Markdown('/content/batch_directory/lec_1.mmd')
5. OCR of Natively Digital PDFs: Unveiling Precision in Equation Recognition While Comparing with LaTex
Below shown comparison is only for the 3.1 section, i.e, OCR of Natively Digital PDFs. Here, as per my observations, there are some misplacements in the title compared to the original pdf but the OCR has done a good job whilst playing with equations.
![]()
- Tutorial 2
Introduction
This tutorial uses Gradio as an interface to showcase the output of the Nougat model.
Table of Contents
- Installation
- Downloading a Sample PDF
- Downloading Model Weights
- Writing Inference Functions for Gradio App
- Building a Gradio Interface UI
- Conclusion
1. Installation
Before we begin, we need to install the necessary libraries, including Gradio and NOUGAT-OCR. Execute the following commands in your Jupyter Notebook or preferred Python environment:
!pip install gradio -U -q
import gradio as gr
!pip install nougat-ocr -q
2. Downloading a Sample PDF
In this tutorial, we will use a sample PDF for demonstration. You can also apply NOUGAT-OCR to your own PDFs. To download the sample PDF, execute the following code:
# Download a sample pdf file - https://arxiv.org/pdf/2308.13418.pdf (nougat paper)
import requests
import os
# create a new input directory for pdf downloads
if not os.path.exists("input"):
os.mkdir("input")
def get_pdf(pdf_link):
# Send a GET request to the PDF link
response = requests.get(pdf_link)
if response.status_code == 200:
# Save the PDF content to a local file
with open("input/nougat.pdf", 'wb') as pdf_file:
pdf_file.write(response.content)
print("PDF downloaded successfully.")
else:
print("Failed to download the PDF.")
return
get_pdf("https://arxiv.org/pdf/2308.13418.pdf")
3. Downloading Model Weights
from nougat.utils.checkpoint import get_checkpoint
CHECKPOINT = get_checkpoint('nougat')
4. Writing Inference Functions for Gradio App
This code provides functions to download PDFs from given links, run NOUGAT-OCR on PDFs, and process PDFs into markdown content. It also includes CSS styling for a Gradio app's markdown display. These functions enable users to convert PDFs to markdown using the Gradio app.
import subprocess
import uuid
import requests
import re
# Download pdf from a given link
def get_pdf(pdf_link):
# Generate a unique filename
unique_filename = f"input/downloaded_paper_{uuid.uuid4().hex}.pdf"
# Send a GET request to the PDF link
response = requests.get(pdf_link)
if response.status_code == 200:
# Save the PDF content to a local file
with open(unique_filename, 'wb') as pdf_file:
pdf_file.write(response.content)
print("PDF downloaded successfully.")
else:
print("Failed to download the PDF.")
return unique_filename
# Run nougat on the pdf file
def nougat_ocr(file_name):
# Command to run
cli_command = [
'nougat',
'--out', 'output',
'pdf', file_name,
'--checkpoint', CHECKPOINT,
'--markdown'
]
# Run the command
subprocess.run(cli_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
return
# predict function / driver function
def paper_read(pdf_file, pdf_link):
if pdf_file is None:
if pdf_link == '':
print("No file is uploaded and No link is provided")
return "No data provided. Upload a pdf file or provide a pdf link and try again!"
else:
file_name = get_pdf(pdf_link)
else:
file_name = pdf_file.name
nougat_ocr(file_name)
# Open the file for reading
file_name = file_name.split('/')[-1][:-4]
with open(f'output/{file_name}.mmd', 'r') as file:
content = file.read()
return content
# Handling examples in Gradio app
def process_example(pdf_file,pdf_link):
ocr_content = paper_read(pdf_file,pdf_link)
return gr.update(value=ocr_content)
# fixing the size of markdown component in gradio app
css = """
#mkd {
height: 500px;
overflow: auto;
border: 1px solid #ccc;
}
"""
5. Building a Gradio Interface UI
This code sets up an interactive interface using the Gradio library for running the NOUGAT-OCR tool. Users can upload a PDF or provide a PDF link. When they click the "Run NOUGAT🍫" button, the OCR process is triggered, and the converted content is displayed in the interface. Users can also clear the interface with the "Clear🚿" button. It's a user-friendly way to use NOUGAT-OCR for PDF conversion.
# Gradio Blocks
with gr.Blocks(css =css) as demo:
with gr.Row():
mkd = gr.Markdown('
#### Upload a PDF
',scale=1)
mkd = gr.Markdown('
#### OR
',scale=1)
mkd = gr.Markdown('
#### Provide a PDF link
',scale=1)
with gr.Row(equal_height=True):
pdf_file = gr.File(label='PDF📃', file_count='single', scale=1)
pdf_link = gr.Textbox(placeholder='Enter an arxiv link here', label='PDF link🔗🌐', scale=1)
with gr.Row():
btn = gr.Button('Run NOUGAT🍫')
clr = gr.Button('Clear🚿')
output_headline = gr.Markdown("
### PDF converted into markup language through Nougat-OCR👇:
")
parsed_output = gr.Markdown(r'OCR Output📃🔤',elem_id='mkd', scale=1, latex_delimiters=[{ "left": r"(", "right": r")", "display": False },{ "left": r"[", "right": r"]", "display": True }])
btn.click(paper_read, [pdf_file, pdf_link], parsed_output )
clr.click(lambda : (gr.update(value=None),
gr.update(value=None),
gr.update(value=None)),
[],
[pdf_file, pdf_link, parsed_output]
)
# gr.Examples(
# [["nougat.pdf", ""], [None, "https://arxiv.org/pdf/2308.08316.pdf"]],
# inputs = [pdf_file, pdf_link],
# outputs = parsed_output,
# fn=process_example,
# cache_examples=True,
# label='Click on any examples below to get Nougat OCR results quickly:'
# )
demo.queue()
demo.launch(share=True)
Before adding any link:

After completing the task:

6. Conclusion
In this tutorial, we learnt how to install and use NOUGAT-OCR to convert academic PDFs into a readable markup language and created an interface using Gradio.
Conclusion
The Nougat system represents a groundbreaking advancement in the realm of academic document processing. Its neural optical understanding capabilities, extensive training data, and user-friendly interface make it a valuable tool for researchers across disciplines. With Nougat, the task of working with academic papers becomes more efficient, opening up new possibilities for research and discovery.
As the academic landscape continues to evolve, Nougat stands as a testament to the potential of machine learning and artificial intelligence in transforming the way we interact with knowledge. Whether you're a seasoned researcher or a student embarking on your academic journey, Nougat is a tool worth exploring. It has the power to enhance your research capabilities and expand the horizons of academic discovery.
References and Further Learning
To delve deeper into Nougat's technical details and to access additional resources, refer to the following:
- Nougat Documentation: Detailed guidance on utilizing Nougat effectively.
- Nougat Research Paper: A comprehensive source for understanding the model's architecture and functionality.
- Nougat GitHub Repository: Access the codebase and contribute to its development.
- Quantum Physics I from MIT OpenCourseWare.
- The Fundamental Equations of Quantum Mechanics by Paul Dirac from the Proceedings of the Royal Society of London.
- The Postulates of Quantum Mechanics from the University of Sydney.