A security audit requires you to think like a hacker.
Security audits involve evaluating your vulnerabilities and assessing the current security measures and how well do they perform in case of an attempted hack.
We know that Magento is one of the most popular open-source Content Management Systems for e-commerce in the market today and deals with sensitive payment info on a daily basis.
This enormous financial data quite obviously caught the eye of hackers. As a result, Magento is threatened continuously with attacks. These threats vary in the form of automated bad bots to a sophisticated hacker attack.
Uncovering all vulnerabilities & loopholes in your website is the first step in securing it.
This article explains to you how to perform a complete security audit of your Magento store. Also, mentioned are remedial solutions to some issues discovered while performing a Magento security audit.
1. Identify Audit Areas: Magento Security Audit
One of the first things that a hacker does on your website is to recognize the type of CMS, server OS, and other basic details such as:
- Magento version.
- PHP version.
- Magento Modules.
- Other software technologies.
Knowing this provides a roadmap to the attacker.
For example, if you still use outdated versions of Magento, the attacker can exploit the known vulnerabilities which existed in older versions of Magento.
Hence, the first step in carrying out a Magento security audit remains that you find these details. There are shrewd ways hackers use to know this. I am listing some of these here.
a) Know Magento Version the Automatic Way
"Blind Elephant" is a popular tool of Kali Linux used for identifying the type of CMS being used. To identify the CMS, open the terminal in your Kali and type BlindElephant.py followed by the URL of the website and CMS you wish to scan i.e.
BlindElephant.py http://192.168.1.252/ Magento.
For more help, type:
BlindElephant.py -h
After the CMS has been confirmed as Magento, to further enumerate the CMS specific details, use MageScan.
MageScan is a tool that can discover not only the Magento version but, installed modules, catalog info, etc. To download and use this tool, visit its Github repo.
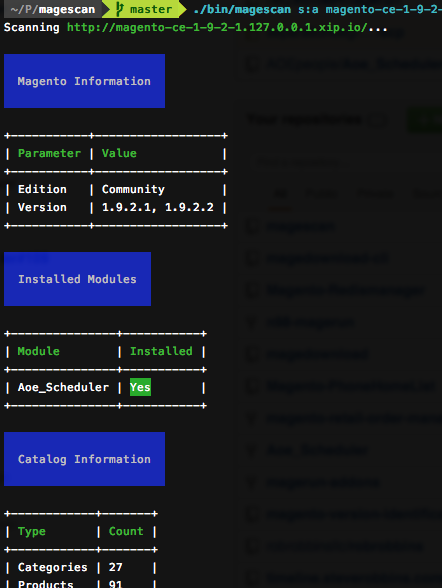
MageScan uncovering details of a Magento site
b) Know Magento Version the Manual Way
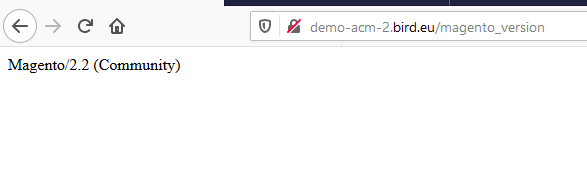
In Magento 2, it has become easier to check the Magento Version that is being used.
Simply append "/magento_version" after the website name, and lo behold! It shall reveal to you the Magento version and to everyone else including automated tools.
Remediation
- If your Magento version is outdated, update it now!
- If you still use Magento 1, migrate to Magento 2.
- Use the latest Magento version i.e. Magento 2.3.x.
- Do not use outdated, ill-reputed modules.
- Use custom error messages.
- To hide your Magento version, connect to your site via SSH and execute the following command:
php bin/magento module:disable Magento_Version
2. Discover Content: Magento Security Audit
Once the Magento version has been discovered, the next step is to discover content i.e. Magneto directories, Admin Panel, etc.
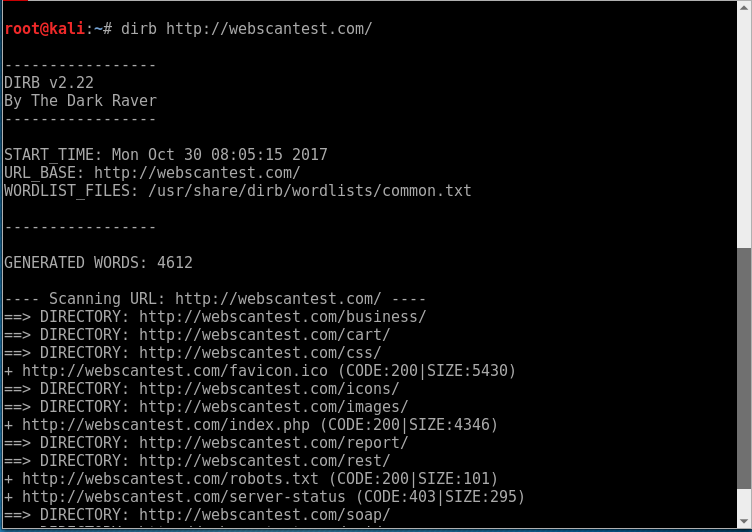
Tools like Dirb can brute force and discover various common directories and files.
In case the directories do not have proper permissions, they can leak sensitive info to the attackers. Moreover, if the admin path is set to default (www.example.com/admin/), the attackers can discover and brute force login to your Magento store.
To brute-force, the directories on your site, open up the terminal in Kali and type "dirb" followed by your site URL. i.e.
Remediations
- Set proper file and folder permissions.
- Enable two-factor authentication.
- Do not use weak or default passwords.
- Configure Captcha in Magento 2 by visiting Stores<Configuration<Customer<Customer Configuration<Captcha.
- To change the default admin path, connect to your site via SSH and run the following command:
php bin/magentosetup:config:set --backend-frontname="myAdmin"
Replace myAdmin with any random name of your choice.
3. Find Server Misconfigurations: Magento Security Audit
While the original CMS may be secure, it is quite possible that there may be some vulnerabilities on your server. These vulnerabilities also need to be checked during a security audit. Some common server misconfigurations that you can check during a Magento security audit are:
a) Open Ports
Open ports imply that a certain TCP or UDP port is accepting packets. Most probably, there is a service running behind an open port.
While an open port in itself is not a bad thing but, services running behind an open port can be exploited by an attacker.
To check if your server has some open ports, NMAP is undoubtedly the best tool there is. It can:
- Scan for open ports.
- Fingerprint OS.
- NSE scripts can be used for a variety of security audits like checking DDOS vulnerability, Heartbleed check, etc.
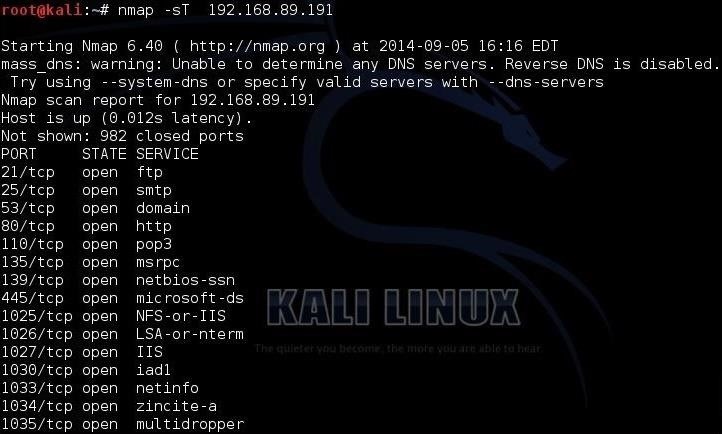
To scan TCP ports on your server, open up the terminal in Kali and type:
nmap -sT xxx.xxx.xxx.xxx
Replace the xxx.xxx.xxx.xxx with IP address you wish to scan for.
b) Weak Cryptographic Implementations
Cryptography plays a vital role in ensuring that the communication between your Magento store and clients is secure. So, one such application of cryptography is SSL. If your site does not have an SSL certificate get one now!
In case you use SSL, make sure that it is not vulnerable to bugs like Poodle, Heartbleed, etc. To check SSL implementation on your Magento store for free visit this site.
Nmap scripts can also be used to check for SSL vulnerabilities like Heartbleed. Just open the terminal in Kali and type:
nmap -sV -p 443 --script=ssl-heartbleed xxx.xxx.xxx.xxx
Now replace xxx.xxx.xxx.xxx with the IP of server you want to scan. Similarly, you can use Nmap scripts to scan for other vulnerabilities like drown, poodle, etc.
Remediations
- Use a firewall to block open ports.
- Use SSL.
- Avoid using weak ciphers.
- Avoid using shared hosting. Use a dedicated VPS if possible.
4. Eliminate Injection Vulnerabilities
Various types of injection vulnerability arise due to poor coding standards. Therefore, they regularly feature in OWASP top 10 vulnerabilities. Although, chances of finding an injection vulnerability in Magento core by you are rare (unless you are a security expert) but plausible. Since Magento is open-source, security researchers have found various XSS, CSRF, SQLi bugs in the past. What you can do is vet the various Magento extensions for injection vulnerabilities.
a) SQL Injection
SQLi is caused when the user input is not properly sanitized and it reaches the database and gets executed. The results can be disastrous for your Magento store as the attackers can get hold of login credentials and inject spam, credit card skimmers, etc.
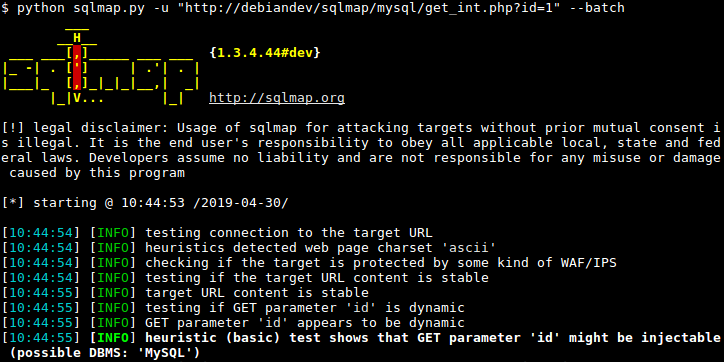
To audit your Magento store for SQLi, perhaps there is no better tool than Sqlmap. This tool can automatically find and exploit SQLi bugs.
To use Sqlmap, open the terminal in Kali and type:
sqlmap -u "www.your-site.com/file?param1=¶m2=" --batch
Here replace your-site.com with the site you wish to audit. The param1 and param2 stand for the parameters you wish to check SQLi for. This is just a simple explanation, for more details type:
sqlmap -h
b) Cross-Site Scripting
Not surprisingly, XSS is also caused due to a lack of proper user input sanitization. By exploiting an XSS, the attacker can run malicious JavaScript on your server. Not going into much into the detail, all you should know is that whatever malicious things an attacker can do using JavaScript can all be done by exploiting an XSS bug.
So, to audit your Magento extensions for any XSS bug, the most suited tool is the Xsser. This tool can even bypass certain web application firewalls and exploit an XSS bug. Also, for novice users, the GUI option is available too.
To learn how to use it, open the terminal in Kali and type:
xsser -h
Remediations
- Follow secure development practices i.e. using prepared statements, implementing CSRF tokens, etc.
- All user input should be sanitized.
5. Identify Business Logic Flaws
Business logic defines the processing and flow of data on your Magento store. In simple words, the user logs in; selects an item; adds it to the cart; then goes to the checkout page and finally pays to complete the process. All these constitute your business logic.
A business logic flaw, therefore, means that due to a lack of proper safeguards, the malicious user can control any of these steps. For instance, the user can edit the rate of an item on your Magento store and buys it for a lower price or even free!
This is just one example, there is a number of possible things that can go wrong. What makes Magento business logic flaws more serious is that they cannot be detected by security scanners.
Also, when a business logic flaw is exploited by the attacker, the firewall or IDS (Intrusion Detection System) may have no idea what's going on.
Remediations
- Chances of finding business logic flaws in the Magento core are very low. But if you use extensions then seriously consider looking for the business logic flaws in them.
Conclusion
To conclude, it can be said that the Magento security audit can be conducted with minimal resources.
However, there are a lot of things that can go wrong. Covering all is beyond the scope of this article but a blueprint has been given.
So, the least you can do as a regular user is to follow Magento security best practices (including regular security audits). These security measures will harden your Magento website’s security against most cyber ills.
Tell us how you liked this blog post in the comments.