A growing number of businesses are using machine learning and complex data analytics to solve various challenges. Businesses can benefit from unstructured data to the fullest extent through text classification. This article speculates the necessity of recognizing fake text from the real ones. It explains the profound character of Machine Learning and Natural Language Processing to accomplish the task. It reveals the extremity of fake text and its coexisting impact on society. This incites on building a system that detects the fake text at the right time. This article encourages one to understand how easily Machine Learning can be used to build an application to spot real and fake text. It describes ways to overcome challenges while creating the applications.
Introduction
The trailing succession of digital mechanisms has been proven to be a determined crowd-puller. Growing technologies like Machine Learning and Natural Language Processing have leveraged tremendous advantages for the well-being of society. Figure 1 represents the impact of fake data on humans. Machine Learning helps society in spreading awareness and creates a positive environment for the society. It has transformed the degree of simplicity in the lives of people. But just as ease of living is a boon to humanity, likewise trusting the information around the globe raises the question on right utilization of technology.
Digital and social media platforms also tend to become a medium of spreading fake information and mislead people [1]. Taking over other people's accounts is a popular tactic used to conceal the provenance of the organization propagating false information. At the same time, technology for fake news detection would restrict this form of defamation, thereby benefiting the society.

Figure 1: Aspects of Machine Learning impacting positively on society
Despite the fact that fake news is widely circulated on social media, research shows that human practice is more responsible for the propagation of false information than automated bots. This demonstrates that there are other options besides battling the fake news sender. Considering the politics of the nation, fake news has grown to be a key factor of both limited and maximal clashes since it is regularly used to target minorities. To fight false data, Google has unveiled a brand-new tool called "About This Result." Users can evaluate information and comprehend its source as it is accessible worldwide. It supports nine Indian languages, including Hindi, Tamil, Bengali, Marathi, Gujarati, Telugu, Malayalam, Kannada, and Punjabi. By giving consumers more context, the feature enables them to choose which websites to visit and how to get the best possible outcomes [2].
Therefore, raising public knowledge and media literacy is a crucial component of fake news detection. Spotting the difference in fake and real information at the right time is highly essential for the betterment of society.
Building the Machine Learning Model
As Machine Learning works with numerical features, it requires the textual data to be converted to numerical data. After this, data pre-processing is carried out using Natural Language Processing. Figure 2 represents the step-by-step process to spot the difference in real and fake data.
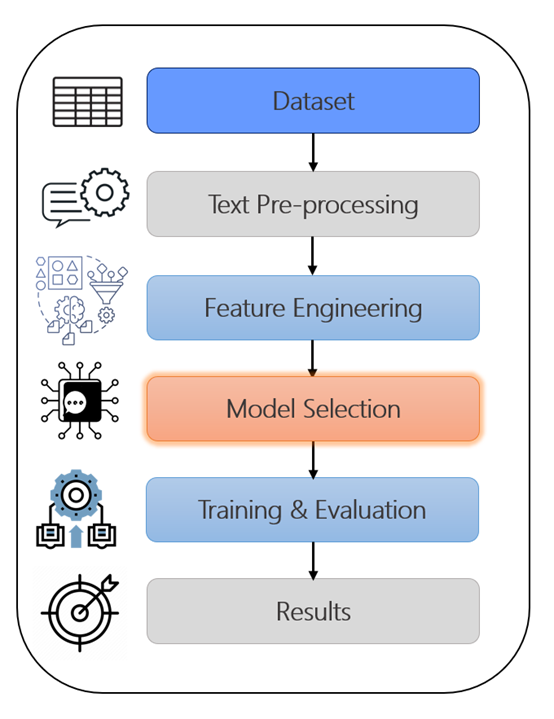
Figure 2: Block architecture to build Machine Learning model
Data Pre-processing
Text pre-processing is the process of removing stopwords, special symbols, and numbers from the text as well as stemming and lemmatization. The text data must be fed into a vectorizer after data cleaning so that it can be transformed into numerical features.
Stop words are used to remove unnecessary words so that the system can concentrate on those that are essential. Example: {is, a, an, the, but, for, on} are the words that do not change the meaning of a sentence when they are removed.
Stemming is a method for eliminating affixes from words to reveal their basic form. It is equivalent to trimming the tree's branches back to the trunk.
Lemmatization is a word normalization technique which takes context into account and reduces a term to its logical base form, or lemma.
Vectorization is the process in which the words are converted to integers or floating-point numbers in order to be used as inputs in machine learning methods
The table 1 below differentiates among the two techniques:
.png)
Table 1: Difference in Stemming and Lemmatization
Feature Engineering
Both of these concepts can be employed for word embeddings, where the words will be transformed into vectors or numbers.
1. Bag-of-Words (BOW) or Count Vectorizer
Primary purpose of a bag of words is to count the word's occurrence in the sentence while ignoring any semantic information. The idea is fairly simple to understand and has been put into exercise. Every word in a bag of words has a number assigned to it, which gives each word equal weight. We make advantage of the TF-IDF paradigm to overcome this.
2. Tf-idf (Term frequency and inverse document frequency)
This model gathers some semantic information by emphasizing unusual words over common terms. The phrase "IDF" refers to giving a greater weight to unusual phrases in the document which makes it more efficient.
Model Selection
Model selection is the process of selecting a Machine Learning model that best fits our data and ultimately results better when evaluated. The table 2 below represents a comparative analysis of various Machine Learning models.

Table 2: Comparative analysis of Machine Learning models
Different models perform better with certain types of data as described in table 2. For instance, Naive Bayes works well when characteristics are very independent. SVM is effective when there are too many features and a moderate sized dataset. Linear regression, logistic regression, and SVM are all effective when there is a linear relationship between the dependent and independent variables. The right knowledge about these models will definitely assist an individual in selecting a model that best suits their data. If one is still unable to decide on just one Machine Learning algorithm, all the models can be compared and examined on the basis of their accuracy on the training and test sets. This will surely help in figuring out the appropriate model for their data.
An ML Model makes decisions based on what it has learned from the data, whereas a neural network arranges algorithms so that it can make decisions reliably on its own. Deep learning is a subset of machine learning, and neural networks are the foundation of deep learning algorithms.
Traditional or "non-deep" machine learning is more centered on human input. Deep learning automizes the majority of the feature extraction phase which in turn reduces the need for manual input from humans. Deep learning models like Convolutional Neural Networks (CNNs) perform efficiently on classifying images. CNNs also excel at image processing tasks such as signal processing and image segmentation. It has the ability to take in the non-labelled data in its unprocessed form and automatically identify the essential features that differentiate them to their original category.
Model Training and Evaluation
Model training is the process of dividing the dataset into training set, validation set and testing set. It is performed to train the model and make it learn about the data in order to understand and identify the good values of each feature in the data. Figure 3 below represents the splitting of the overall dataset.

Figure 3: Splitting the data for model training
The training phase uses up to 75% of the whole dataset. The training set is used to assign the weights and biases that go into the model. For the validation set, almost 15% to 20% of the data is utilized to assess initial accuracy and concurrently modify its hyperparameters. The validation data is seen by the model, but it is not utilized to learn weights and biases. And the test set uses the remaining 5% to 10% of the data for model evaluation. This data is unseen by the model and it is then tested on the basis of new data.
Model Evaluation
Any model is evaluated on the basis of matrices. They are calculated on the basis of true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN). Model evaluation is the practice of leveraging multiple evaluation measures to analyze a model's performance, abilities and shortcomings. A few basic metrics used to evaluate the model are mentioned below:
1. Accuracy
Accuracy is defined as the ratio of the number of correct predictions to the total number of predictions.
Accuracy = (TP+TN)/(TP+TN+FP+FN)
2. Precision
Precision is the ratio of true positives to the total of true positives and false positives. It basically analyzes the positive predictions.
Precision = TP/(TP+FP)
3. Recall
Recall is the ratio of true positives to the total of true positives and false negatives. It basically analyzes the number of correct positive samples.
Recall = TP/(TP+FN)
4. F1-Score
The F1 score is the harmonic mean of precision and recall. It is seen that during the precision-recall trade-off if we increase the precision, recall decreases and vice versa.
F1 score = (2×Precision×Recall)/ (Precision + Recall)
Deploying and Using the Application
Model Deployment
The Machine Learning model can be moved to the deployment phase, once the model is tested and evaluated. The model can be deployed using three different environments. Google AI Platform offers a good option for building and subsequently deploying Machine Learning models. Various platforms offer deployment options for Machine Learning models, like AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, Google App Engine as well as Google cloud. These platforms are for people who have built a machine learning model locally and are looking into possible deployment platforms.
Application Usage
The input to the system can be textual data or a piece of information. The ML model will process the data and classify it as a real or fake text. The most important step in preventing the spread of fake news and saving people's lives is early fake news identification [3]. Another challenge in identifying fake text is the shortage of large datasets as well as labeled datasets marked with ground-truth labels [4].
Conclusion
Supporting people's understanding that their news-consuming behaviors, such as liking, commenting, and sharing, might have a big impact. There is a need to create a system that keeps track of people's news-related behaviors, analyzes similarities and differences between those behaviors, and displays these actions or patterns to individuals.