In a typical AI application trained on a vast corpus of data, the model may not have access to specific, customized data, leading to less accurate or relevant responses. However, with Retrieval-Augmented Generation (RAG), businesses can provide their own data to the AI application. RAG allows the AI to retrieve and utilize this custom data to generate more precise and contextually accurate responses.
Additionally, RAG enhances data security. In many situations, businesses may not want to share proprietary or sensitive data with AI companies due to privacy or security concerns. By using RAG, they can keep their data private and secure while still benefiting from the AI's capabilities. This approach ensures that the data is used solely within a controlled environment, mitigating the risks associated with data sharing.
To understand the process, let's go through the various steps involved in building a Retrieval Augmented Generation (RAG) application step by step.
The Tools We Shall Use
PGVector
First, we’ll convert our data into embeddings, which are numerical representations of the data that capture its semantic meaning. To efficiently manage these embeddings, we’ll use a PGVector container to store them. This approach allows us to retrieve the embeddings whenever needed without having to convert the data each time. Converting data into embeddings repeatedly can be time-consuming and resource-intensive, requiring significant computational power and money. By storing our embeddings in a PGVector container, we avoid this repetitive and costly process, ensuring that our embedded data is readily available for quick and efficient retrieval.
The PGVector extension for PostgreSQL is a tool that helps you work with vectors right inside your database. Here's a breakdown of the key concepts in simpler terms:
What Does PGVector Do?
Storage: It allows you to store vectors in your PostgreSQL database.
Manipulation: You can change and work with these vectors easily.
Querying: It provides tools to search and analyze vector data efficiently.
LangChain
LangChain is a framework designed to streamline the development of applications utilizing large language models (LLMs). As a language model integration framework, LangChain supports a wide range of use cases including document analysis and summarization, and chatbots.
Llama 3
Llama 3 is the next-generation open-source LLM developed by Meta that's been trained on internet-scale data. This allows it to understand and comprehensively respond to language, making it suitable for tasks like writing creative content, translating languages, and answering queries in an informative way.
Gradio UI
Gradio is an open-source Python package that allows you to quickly build a demo or web application for your machine learning model, API, or any Python function. You can then share a link to your demo or web application in just a few seconds using Gradio's built-in sharing features.
E2E Cloud
E2E’s AI development platform, TIR, allows you to host LLMs and fine-tune them easily. TIR has seamless integration with PGVector and Llama 3 – and we can use that as well as an alternative deployment option.
Ollama
Ollama is a streamlined open-source tool used for running open-source LLMs locally, like Llama 2, Mistral, Falcon, etc. Ollama bundles all the necessary ingredients for the model to function locally including model core data (weights), instruction (configuration), and dataset into a neat package managed by a modelfile.
To use Ollama, one simply needs to download it from the website. It's available for macOS, Linux, and Windows.
Let's Code
Since we are working with a locally deployed LLM, we need an advanced GPU for our task. E2E Cloud provides a range of GPUs geared towards building AI applications. You can check out the offerings at https://myaccount.e2enetworks.com/.
Go ahead and register, and then launch a GPU node. Alternatively, you can head to TIR and launch a Llama 3 endpoint and a PGVector endpoint.
Loading all the libraries:
import gradio as gr
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
Load the text and split it into manageable chunks.
To simulate real-time data updates, we are using the Faker library to generate dynamic data. Here, we’re creating log files and refreshing the data every 60 seconds. You can customize it with your own real-time data as needed.
# Initialize Faker for generating fake data
fake = Faker()
# Configure logging with direct file path
log_file_path = "Path_to_file"
logging.basicConfig(filename=log_file_path, level=logging.DEBUG, format='%(asctime)s - %(message)s')
# Function to generate fake log data with detailed text content
def generate_fake_logs():
for _ in range(1): # Generate 1 log entry each time
# Generate a random timestamp
timestamp = time.strftime('%Y-%m-%dT%H:%M:%S.') + str(random.randint(100000, 999999))
ip_address = ".".join(str(random.randint(0, 255)) for _ in range(4))
user_agent = fake.user_agent()
details_text = fake.paragraph(nb_sentences=5)
# Generate the log entry with detaile
log_entry = f"{timestamp} - {ip_address} - {user_agent} - {details_text}"
# Write the log entry to the log file
logging.info(log_entry)
# Function to update the log file with new log data
def update_log_file():
while True:
generate_fake_logs() # Generate new log data
logging.info("Updating log file with new data")
time.sleep(60) # Wait for 1 minute before updating again
# Start a thread to update the log file in the background
log_thread = threading.Thread(target=update_log_file)
log_thread.daemon = True
log_thread.start()
# Function to load and reprocess the document
def load_and_reprocess_documents():
loader = TextLoader(log_file_path)
documents = loader.load()
return documents
# Function to add documents to the vector store
def update_vector_store():
my_logs = load_and_reprocess_documents()
vectorstore.add_documents(my_logs, replace=True)
# Initially load and add documents to the vector store
update_vector_store()
Connecting to PGVector database and storing embedding:
You can run the following command to spin up a Postgres container with the PGVector extension:
docker run --name pgvector-container -e POSTGRES_USER=langchain -e POSTGRES_PASSWORD=langchain -e POSTGRES_DB=langchain -p 6024:5432 -d pgvector/pgvector:pg16
# Database connection string
connection ="postgresql+psycopg://langchain:langchain@localhost:6024/langchain"
collection_name = "my_docs" # Name of the collection in the database
vectorstore = PGVector(
embeddings=embeddings, # Use the initialized embeddings
collection_name=collection_name, # Specify the collection name
connection=connection, # Database connection
use_jsonb=True, )
Once our connection to PGVector is established and we’ve created our container, we can start adding real-time data using the code below. Then we’ll use a retriever to access the stored embeddings when needed.
Initialize the LLM model. Make sure you’ve installed Ollama on your system, launched an Ollama server, and pulled Llama 3. You can follow the instructions here.
Download Ollama - Link
After downloading, you can run the model locally by using simple code on your terminal. -
> ollama run llama3

# Initialize the language model
llm = Ollama(model="llama3")
# Initialize the RetrievalQA
qa_stuff = RetrievalQA.from_chain_type(
llm=llm, # Use the initialized language model
chain_type="stuff", # Specify the chain type
retriever=retriever, # Use the created retriever
verbose=True, # Enable verbose mode for debugging
)
Finally getting the query back and also creating the Gradio UI interface.
# Function to handle the query
def get_answer(query):
update_vector_store() # Update the vector store with the latest content
response = qa_stuff.run(query) # Run the QA chain with the query
return response # Return the response
# Create a Gradio interface
iface = gr.Interface(
fn=get_answer, # Function to handle the query
inputs="text",
outputs="text", # Output type for the interface
title="llama 3 RAG", # Title of the Gradio interface
description="Ask a question and get an answer:",)
# Launch the interface
iface.launch(inline=True)
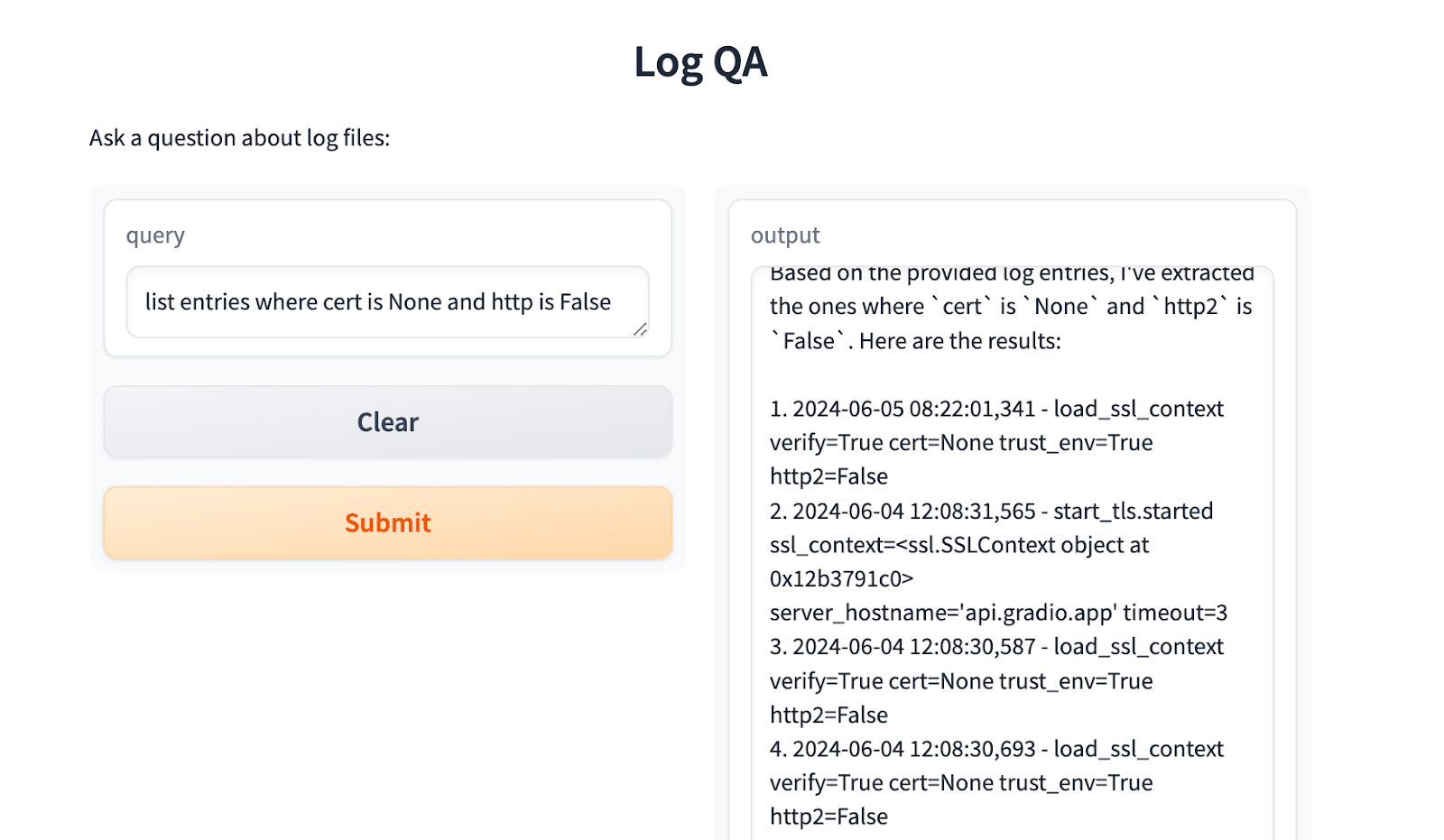
Below is the response I received:
Conclusion
By leveraging Retrieval Augmented Generation (RAG), you can create a customized chatbot that is both highly accurate and secure, tailored specifically to your data. Tools like Gradio UI and Streamlit facilitate the creation of visually appealing interfaces with ease, enhancing the user experience.In applications like customer support, knowledge management, and information retrieval, users often ask complex questions that require detailed and precise answers. Traditional natural language processing (NLP) systems, including both retrieval-based and generation-based models, face significant challenges in delivering high-quality responses.
To easily build and deploy these advanced solutions, platforms like E2E Cloud’s TIR AI model deployment platform offer smooth and reliable infrastructure support, helping you develop, train, and launch your RAG-powered chatbots with confidence and ease.