Deep learning and other AI and ML algorithms are widely used by large organizations and startups for various day-to-day activities. One of the uses of these technologies is for text detection and recognition.
Text detection and recognition have emerged as a significant problem in recent years. This trend has resulted from advancements in the fields of computer vision and machine learning, as well as an increase in applications based on text detection and recognition.
Text detection and recognition from video captions and online pages are also gaining popularity. Much research has been conducted on the topic of text identification and extraction from images. There are various recognition techniques available. Still, a problem with Text detection and recognition is not fully resolved. Text extraction and segmentation from natural scenes are possible. It is still extremely tough to achieve.
In this blog, we will discuss deep convolutional and recurrent neural networks for end-to-end, open-vocabulary text reading on historical maps. A text detection network can anticipate word bounding boxes at any direction and scale. The identified word pictures are then normalized in preparation for use in a robust recognition network.

Figure: Detected text rectangles (predicted baseline in blue)
What are Historical Maps and Problems associated with them?
A historical map is a map that was drawn or printed in the past to promote the study and comprehension of the geography or geographical ideas of the time and place in which it was created or a historical map is a modern map that depicts a past geographical situation or event.
A map of Delhi published in 1775 is considered historic, and a map made in 2002 to depict Delhi in 1775 is considered historical. Old maps, like old texts, can be difficult to decipher. They differ from modern maps due to their age. They frequently utilize different symbols and were drawn or printed using different procedures than traditional maps. Text on these historical maps can appear in almost any orientation, in a variety of sizes, and alongside graphical components or even add text within the local field of view.
Methodology used
Bringing map document processing into the deep learning era may aid in the elimination of the requirement for complex algorithm creation. Deep-learning models and methodologies can aid in the discovery and interpretation of map text.
First, because text can appear in practically any orientation on a map, scene text identification algorithms are modified so that the semantic baseline of the text, in addition to its geometric orientation, must be learnt and predicted.
Second, to make text recognition resistant to text-like graphical distractors, a convolutional and recurrent neural network framework is applied. And finally, a synthetic data creation approach that delivers the many training instances required for accurate recognition without overfitting is detailed.
Structure of the extracted features
This model uses both FOTS (Fast oriented text spotting with a unified network) and ResNet50 (Deep residual learning for image recognition), as a convolutional backbone. Deep Neural Networks process the recovered feature maps, which are 1/32,1/16,1/8, and 1/4 the size of the input image, using the same feature-merging branch as the EAST (efficient and accurate scene text detector) which uses PVANet (lightweight deep neural networks for real-time object detection).
DNN employs bilinear upsampling to repeatedly twice the size of a layer's feature map, then applies a 1X1 bottleneck convolution to the concatenated feature maps, followed by a 3X3 feature-fusing convolution. To construct the final feature map used for the output layers, the merged features are subjected to a final 3X3 convolution.
Output Layers
The output convolutional feature map feeds into three dense, fully-convolutional outputs: a score map for predicting the presence of text, a box geometry map for specifying distances to the boundaries of a rotated rectangle, and the angle of rotation. Each output map is 1/4 the size of the input image.
Loss function
Each output layer requires a different loss function, and the "don't care" regions outside the smaller shrink rectangle but inside the ground truth text rectangle are excluded from all loss function calculations.
Furthermore, places, where two ground truth rectangles overlap, are ignored, eliminating the requirement for any prioritizing strategy in estimating edge distances.
Score:

where pi [0, 1] are the score map predictions and ti {0, 1} are the matching ground truth values at each point i.
Rbox: This DNN-based model uses the IoU loss to predict rotated rectangles.

Angle: The cosine loss is simply the rotation angle loss.

The total loss finally is calculated by the below formula:
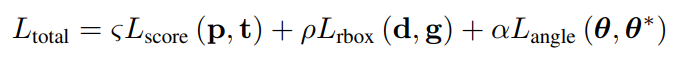
Historic Map Text Recognition
The DNN-based model uses text recognition to recognise text predicted by the detection branch. Use a layered, bidirectional LSTM trained with CTC loss and built on CNN features. Each convolutional layer employs an activation of the ReLU. Every convolutional network in our network layer uses a paired sequence of 3X3 kernels to increase each Feature's theoretical receptive field.
This DNN-based model uses no padding to trim the initial convolution map to only valid replies. Because the kernel is just 3X3, it erodes only a single pixel from the outside edge while keeping the ability to distinguish fine details at the edges using a relatively small pool of 64 first-layer filters. Following this initial stage, the convolutional maps can essentially learn to generate positive or negative correlations (then ReLU trimmed), implying that zero-padding in the following stages is still appropriate.
After the second convolution of each layer, batch normalization is utilized. Unlike CRNN, including the first two layers adds computation but should reduce the number of iterations required for convergence.
Each character must have at least one horizontal "pixel" in the output feature map. Downsampling horizontally just after the first max pooling step preserves sequence length. As a result, the model is able to distinguish shorter sequences of compact characters. A cropped image of a single character (or digit) can be as small as 8 pixels wide, and two characters can be as small as 10 pixels wide. The input image is normalized to a height of 32 pixels for recognition while keeping the aspect ratio and horizontally extending a clipped section to a minimum width of 8 pixels.
Map word image synthesis
The map word picture synthesis process is divided into three major components. A text layer and a backdrop layer are generated as vector graphics first, then blended and rasterized for post-processing.

Figure: Dynamic map text synthesis pipeline.
Background Layer: Used to aid the recognition model. The synthesizer replicates a wide range of sounds after learning what to ignore. Several cartographic elements make text recognition more difficult The background is separated into several areas, each with its own brilliance. We generate a biased field by picking individuals at random. Anchor points for linear gradients combined with piecewise brightness of the background.
Finally, several types of distractors, thick boundaries, independent lines, and other markers are simulated. Curves (such as rivers, roads, and railroads), grids, parallel lines, and so on curves with changing lengths, ink splotches, points (such as cities) texture and markers (with regular polygons as the textons). A layer of overlapping distractor text is also added for a low likelihood of random locations and orientations.
Text Layer: For rendering, the text caption is selected at random from a list of possible texts or a random sequence of digits, followed by the font (typeface, size, and weight) and letter spacing. Before rotating and presenting the text along a curved baseline, the horizontal scale is changed. To imitate document flaws, circular spots are randomly chopped from the text and the opacity of the layer can be reduced. To simulate inadequate localisation, image padding/cropping is used.
Post-processing: After combining the text with the background layer, we add Gaussian noise to the rasterized image, followed by blur and JPEG compression artifacts.
Conclusion
For automated map comprehension, many tools and domain-specific algorithms have been created. Deep-learning systems can be easily adapted to extract text from complex historical map images given enough training data, as demonstrated by this work.
We anticipate that georectification-provided pixel-specific lexicons will greatly improve end-to-end outcomes, as they have for cropped word recognition.