To increase the performance of the encoder-decoder paradigm for machine translation, the attention mechanism was devised. The attention mechanism was designed to allow the decoder to use the most important sections of the input sequence in a flexible way by using a weighted combination of all of the encoded input vectors, with the most relevant vectors receiving the greatest weights. As attention becomes more prominent in machine learning, so does the number of neural networks that include an attention mechanism.
This blog will teach you about attention-based architecture and how to use it.
What is Attention?
What exactly is attention?
Attention is defined in psychology as the cognitive process of selectively focusing on one or a few objects while disregarding others. A neural network is thought to be an attempt to simulate human brain activities in a reduced fashion. Attention Based architecture is another effort in deep neural networks to achieve the same action of selecting and concentrating on a few significant items while disregarding others.
For instance, Assume you're looking at a group shot of your first school. Typically, a group of youngsters may sit across multiple rows, with the instructor sitting somewhere in between. How will you respond if someone asks, "How many people are there?" Isn't it as simple as counting heads?
You don't need to think about anything else in the picture. If someone asks you, "Who is the instructor in the photo?" your brain will know precisely what to do. It will just begin hunting for adult-like traits in the image. The remaining characteristics will be ignored. This is the 'Attention' that our brain excels at applying.
Attention Based Architecture
The attention technique was developed to overcome the bottleneck problem caused by using a fixed-length encoding vector, in which the decoder has restricted access to the information supplied by the input. This is regarded to be particularly troublesome for lengthy and/or complicated sequences, whose dimensionality would be required to be the same as for shorter or simpler sequences.
The attention mechanism is separated into the following steps for computing the alignment scores, weights, and context vector:
Alignment scores: The alignment model uses the encoded hidden states, hi, and the previous decoder output, St-1, to calculate a score, et,i, that shows how well the input sequence elements fit with the current output at the position, t. The alignment model is represented by a function, a(. ), which a feedforward neural network may implement:
et,i = a(St-1, hi)
Weights: Weights αt,i, are calculated by applying a softmax operation to the previously computed alignment scores:
Αt,i=softmax(et,i)
Context vector: At each time step, a unique context vector, ct, is provided into the decoder. A weighted sum of all, T, encoder hidden states is used to compute it:

Models Based on Attention
Attention-based models present one method for obtaining context vectors c1,c2,...,cU from memory h. Simply put, attention-based models have the ability to examine all of these vectors h1,h2,...,hT in memory and choose which one will be utilised as the context vector supplied to the decoder RNN at each output time step. If hj is used as the ci, we can state that the model is paying attention (or simply attending) to the jth vector in memory at output time step i. We shall shortly learn what procedures may be used to examine memory in order to determine context vectors.
Encoder: The encoder is often a multi-layered bi-directional RNN composed of LSTM or GRU cells. Uni-directional RNNs have also been utilised in some circumstances to analyse input from left to right. Because the entire input sequence is not accessible for speedy decoding, online decoding necessitates uni-directional RNN. When the encoder is bidirectional, vectors h1,h2,...,hT are created by concatenating forward and backward cell outputs.
Decoder: The decoder is typically a multi-layered uni-directional RNN composed of LSTM or GRU cells and an output layer/function. As previously indicated, si represents the current condition of this RNN. The decoder employs prior output yi-1 and context vector ci in addition to its previous state si-1 at each output time step. To generate output yi, the output function employs the current decoder state si and the context vector ci. If the output is categorical, this function may be a trainable softmax layer.
Categorization of Attention-Based Architecture
We may also divide the attention-based architecture into the following categories:
- Self-Attention
- Global/Soft
- Local/Hard
Let's start with an overview of the attention mechanism's categories:
Mechanism of Self-Attention: When an attention-based architecture is applied to a network in such a way that it may relate to various points of the same sequence and calculate the representation of the same sequence, this is referred to as self-attention or intra-attention.
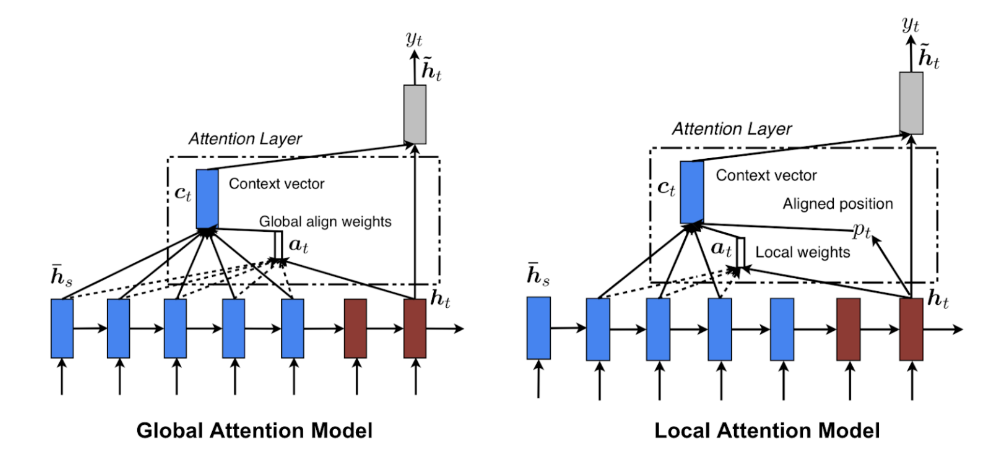
Local/Hard Attention Mechanism: This type of attention mechanism is used when the attention mechanism is applied to specific patches or sequences of data. This form of focus is mostly used for the network's image processing duty.
Soft/Global Attention Mechanism: Every patch or sequence of data is referred to as a Soft/Global Attention Mechanism when the network's attention is focused on learning. This emphasis may be extended to image processing as well as text processing.
Conclusion
The aim of this blog was to give you a thorough examination of the popular Attention-based architecture. I'm sure you can see why attention-based architecture have such an impact in the deep learning arena. It is quite effective and has already infiltrated several sites.