What Is Fine-Tuning an LLM?
Fine-tuning a Large Language Model (LLM) like Mistral 7B involves the process of taking a pre-trained general-purpose language model and training it on a specific dataset to tailor it for particular tasks or to improve its performance on certain types of input.
The original model is trained on a vast corpus of text, which helps it understand language patterns and contexts. This process is known as pre-training and typically involves self-supervised learning, where the model learns to predict missing words or sentences in a given text.
Once the model has been pre-trained, fine-tuning adjusts the model's weights and biases using a smaller, more specialized dataset. This dataset is often annotated, meaning that it provides examples of the input-output pairs the model should learn to handle. For instance, if you're fine-tuning a model for legal document analysis, you would use a dataset of legal text.
Fine-tuning can significantly improve a model's ability to handle domain-specific tasks, such as sentiment analysis on product reviews, question-answering in medical contexts, or language translation for specific language pairs. However, one must be cautious of overfitting, where the model performs well on the training data but poorly on general or unseen data. This is why the fine-tuning dataset should be representative and the evaluation thorough.
How the TIR Platform Streamlines Fine-Tuning
E2E's Foundation Studio streamlines the fine-tuning process with a user-friendly interface and a step-by-step guided approach. Here's how it makes fine-tuning easy for users:
-
Simplified Navigation: The sidebar in Foundation Studio allows users to easily navigate to the "Fine-Tune Models" option, making the start of the fine-tuning process straightforward.
-
Managed Fine-Tuning Jobs: The interface provides a "Manage Fine-Tuning Jobs" page where users can create new jobs or manage existing ones, offering a centralized location for fine-tuning tasks.
-
Guided Job Creation: With the "Create Fine-Tuning Job" feature, users are guided through the process of setting up a fine-tuning job, including naming the job, selecting models, and integrating with Hugging Face if necessary.
-
Dataset Preparation: Users are guided through dataset preparation with clear options for task selection, dataset type, validation split ratio, and prompt configuration. For custom datasets, the platform provides easy upload and management features.
-
Hyperparameter Configuration: Foundation Studio offers a form to input hyperparameters and advanced settings, making it easy for users to customize their fine-tuning process without needing deep technical knowledge of the underlying algorithms.
-
Integration and Debugging: The platform supports integration with tools like WandB for tracking experiments and provides options for debugging, helping users monitor and refine the fine-tuning process.
-
Compute Selection and Job Launch: Users can select the type of machine for the fine-tuning job and launch it directly from the interface, simplifying the resource allocation and job initiation.
-
Model Repository: After the fine-tuning job is complete, the fine-tuned model and all related artifacts are stored in a model repository, which is easily accessible for inference or further analysis.
-
Job Parameter Review: Foundation Studio allows users to view job parameter details in the overview section, providing transparency and the ability to review the settings used for each fine-tuning job.
By abstracting the complexities of fine-tuning and offering a well-organized interface, E2E's Foundation Studio helps users fine-tune models with less effort and technical expertise. This user-centric approach can democratize advanced machine learning techniques, allowing more people to benefit from tailored AI models.
Fine-Tuning Mistral-7B on TIR’s Foundation Studio
Under the Foundation Studio dropdown, click on “Fine Tune Models”.
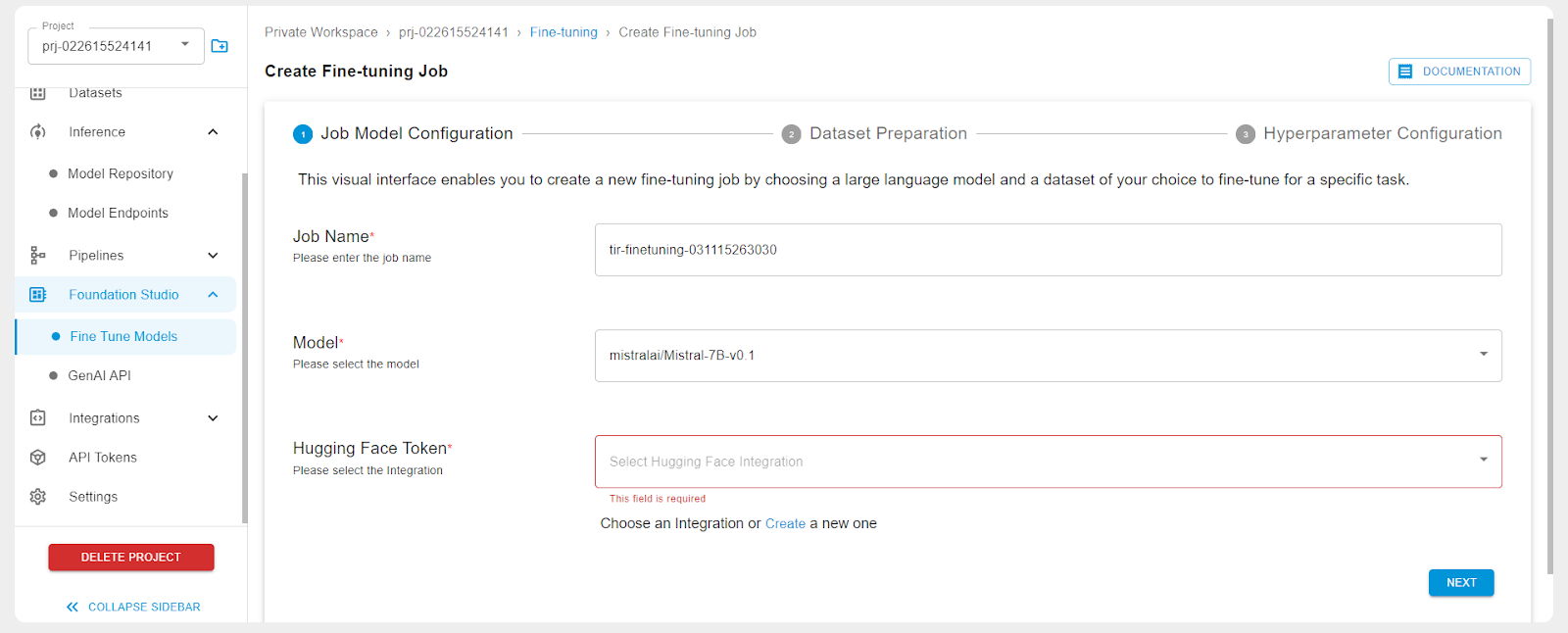
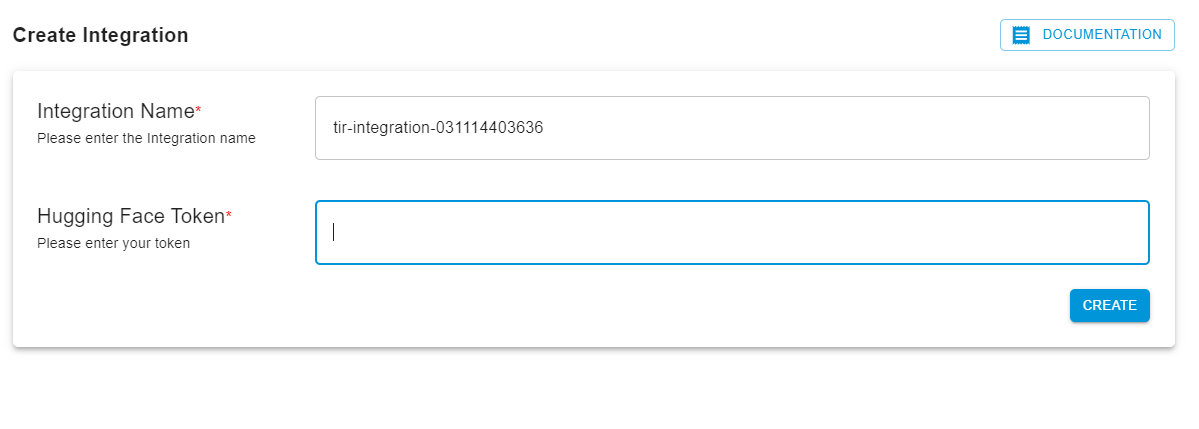
Create a Hugging Face integration for the API token.

You can enter your Hugging Face token here.
You have the option to either select a Hugging Face dataset or go with a custom dataset.
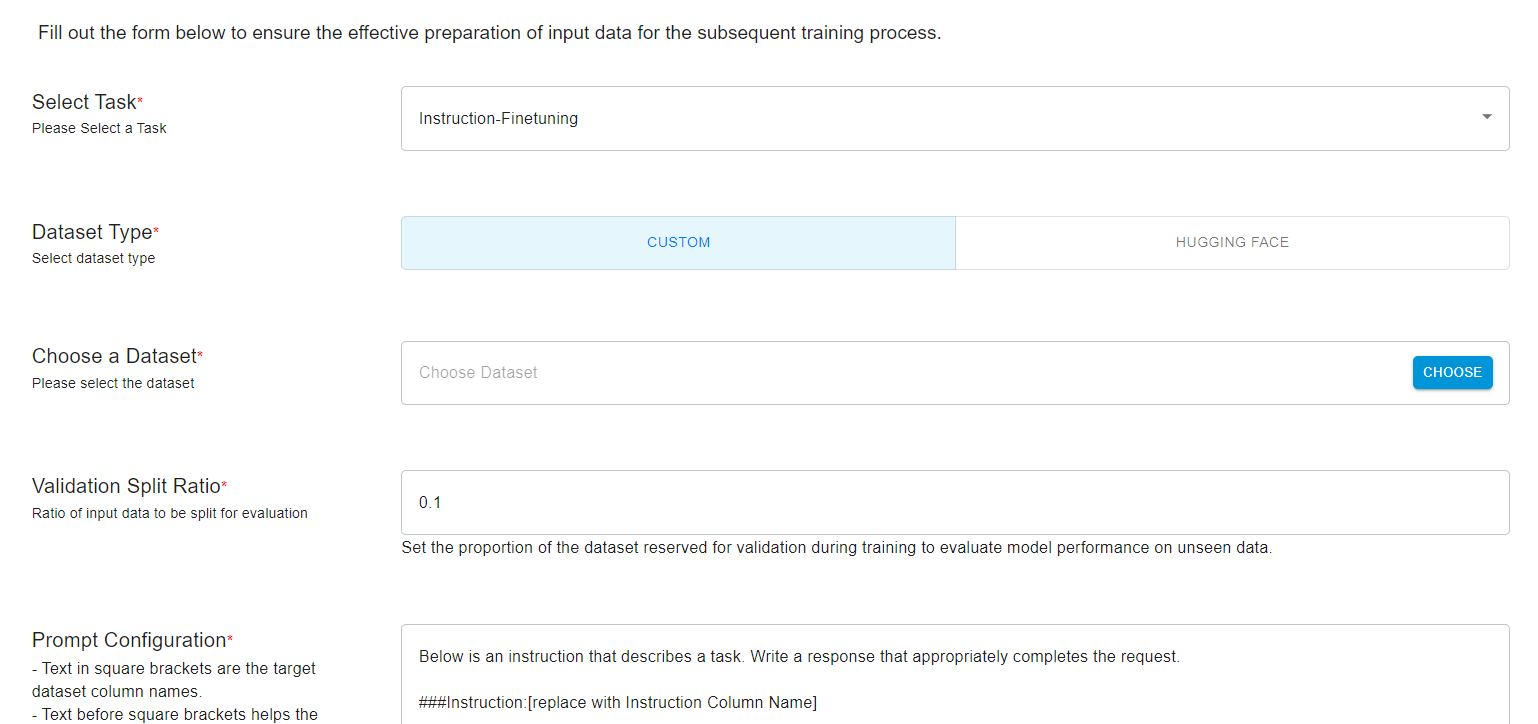
We’ll select a custom dataset so that it gives you an idea of how to work with your unique datasets. The platform expects the dataset to be in JSON format.
I wrote a script to download a Hugging Face dataset and convert it into JSON. We’ll be using Microsoft’s Orca Math Word Problem Dataset.
import json
import subprocess
# Define the curl command
curl_command = [
'curl', '-X', 'GET',
"https://datasets-server.huggingface.co/rows?dataset=microsoft%2Forca-math-word-problems-200k&config=default&split=train&offset=0&length=100"
]
# Run the curl command and capture the output
result = subprocess.run(curl_command, capture_output=True, text=True)
# Check if the curl command was successful
if result.returncode != 0:
print("Error fetching the data:")
print(result.stderr)
else:
# Convert the JSON response to a Python dictionary
data = json.loads(result.stdout)
# Extract the rows and transform them into the desired list of dictionaries with only question and answer keys
simplified_rows = [{'question': row['row']['question'], 'answer': row['row']['answer']} for row in data['rows']]
# Convert the simplified rows to a JSON string
simplified_rows_json = json.dumps(simplified_rows, indent=4)
# Write the simplified rows to a file
with open('simplified_rows.json', 'w') as f:
f.write(simplified_rows_json)
print("simplified_rows.json has been written with the simplified row data.")
The data is stored as simplified_rows.json. We’ll upload this into the TIR datasets. Click on Datasets on the left:
Then create a new dataset.
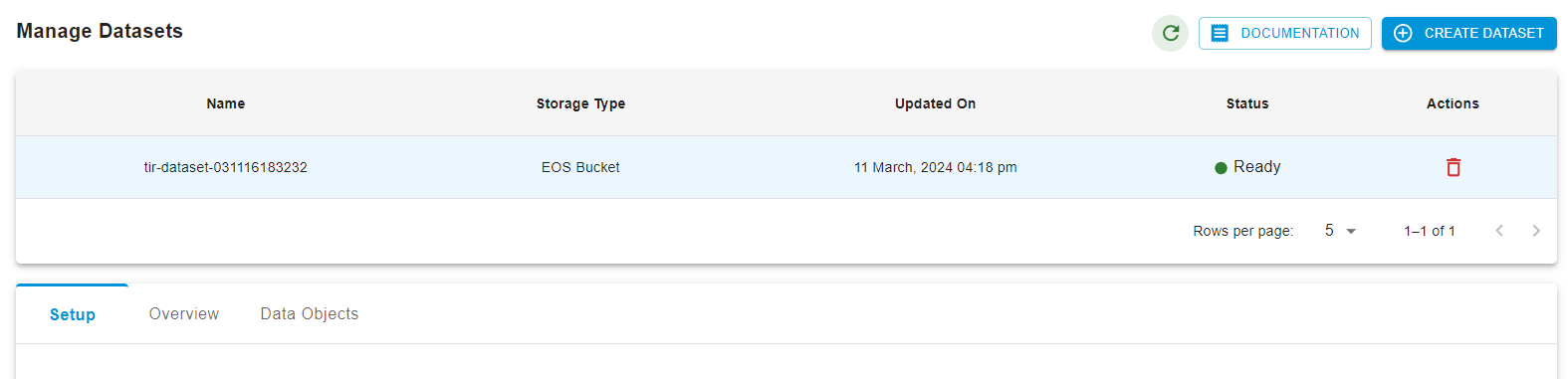
You will see the Setup option below which will guide you as to how you can upload your JSON file to the dataset.
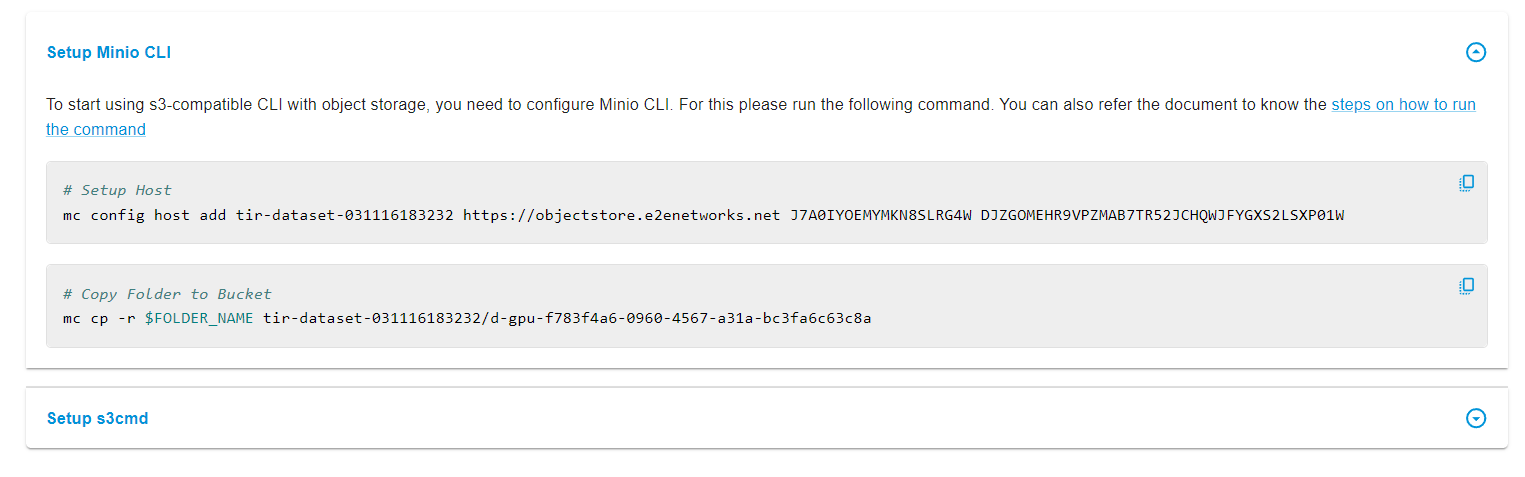
In my case, I had to run the following two commands in my terminal:
mc config host add tir-dataset-031116183232 https://objectstore.e2enetworks.net J7A0IYOEMYMKN8SLRG4W DJZGOMEHR9VPZMAB7TR52JCHQWJFYGXS2LSXP01
mc cp -r simplified_rows.json tir-dataset-031116183232/d-gpu-f783f4a6-0960-4567-a31a-bc3fa6c63c8a
Now if you go to Object Storage in the My Accounts section,
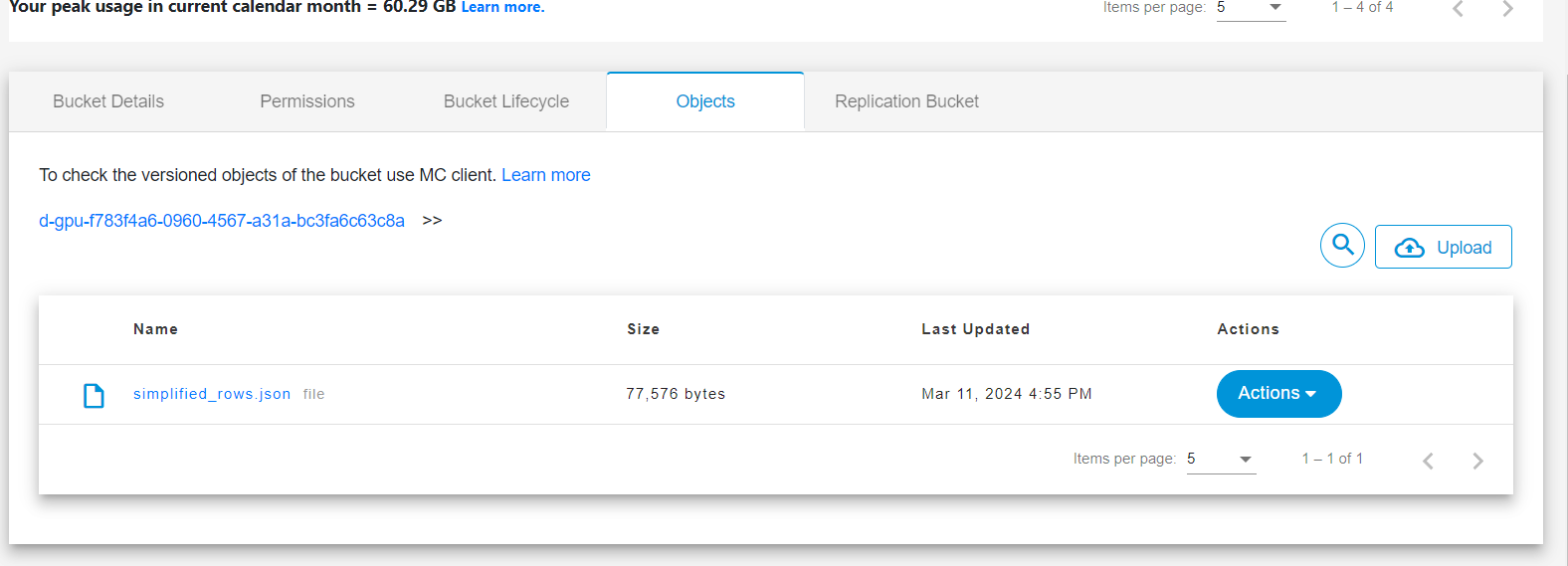
You will find the bucket for your dataset.

Below you can click on the objects and find your data uploaded.
Choose your dataset, and then modify the prompt configurations accordingly.
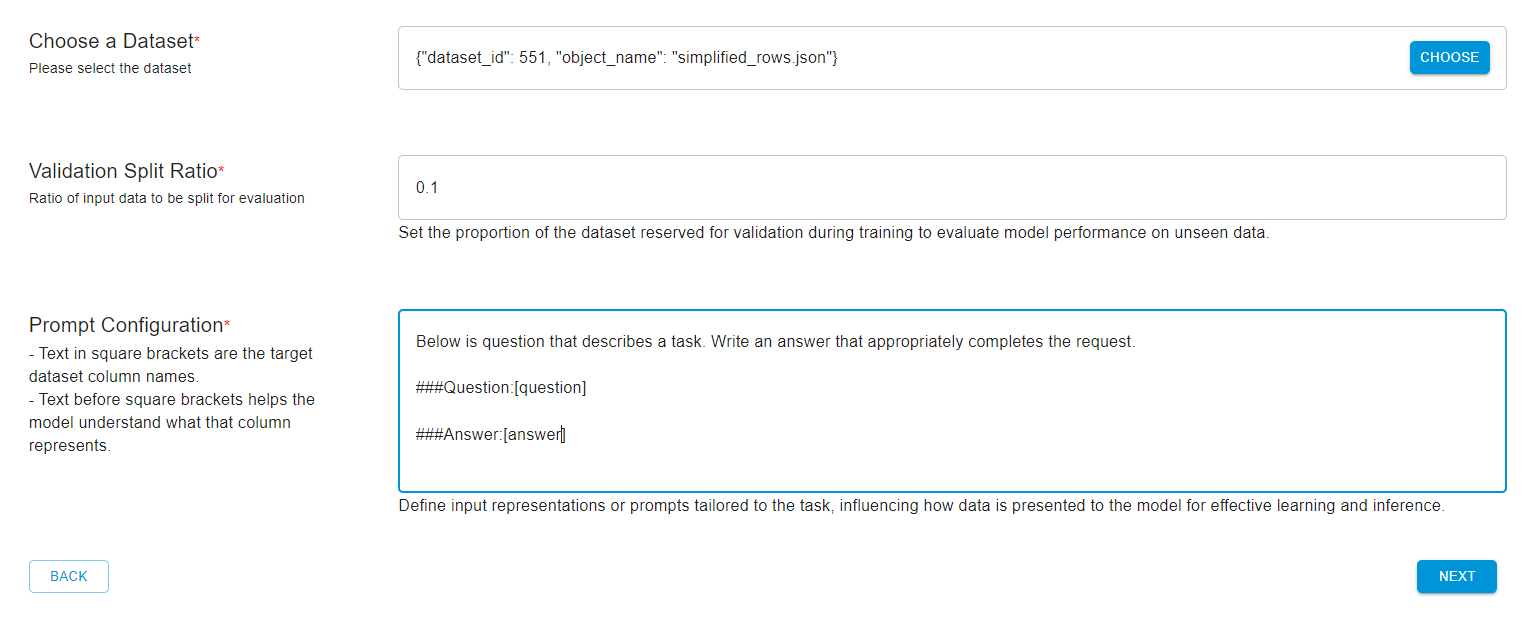
Below is a question that describes a task. Write an answer that appropriately completes the request.
###Question:[question] ###Answer:[answer]
Then click on Next and configure the hyperparameters wherever necessary.
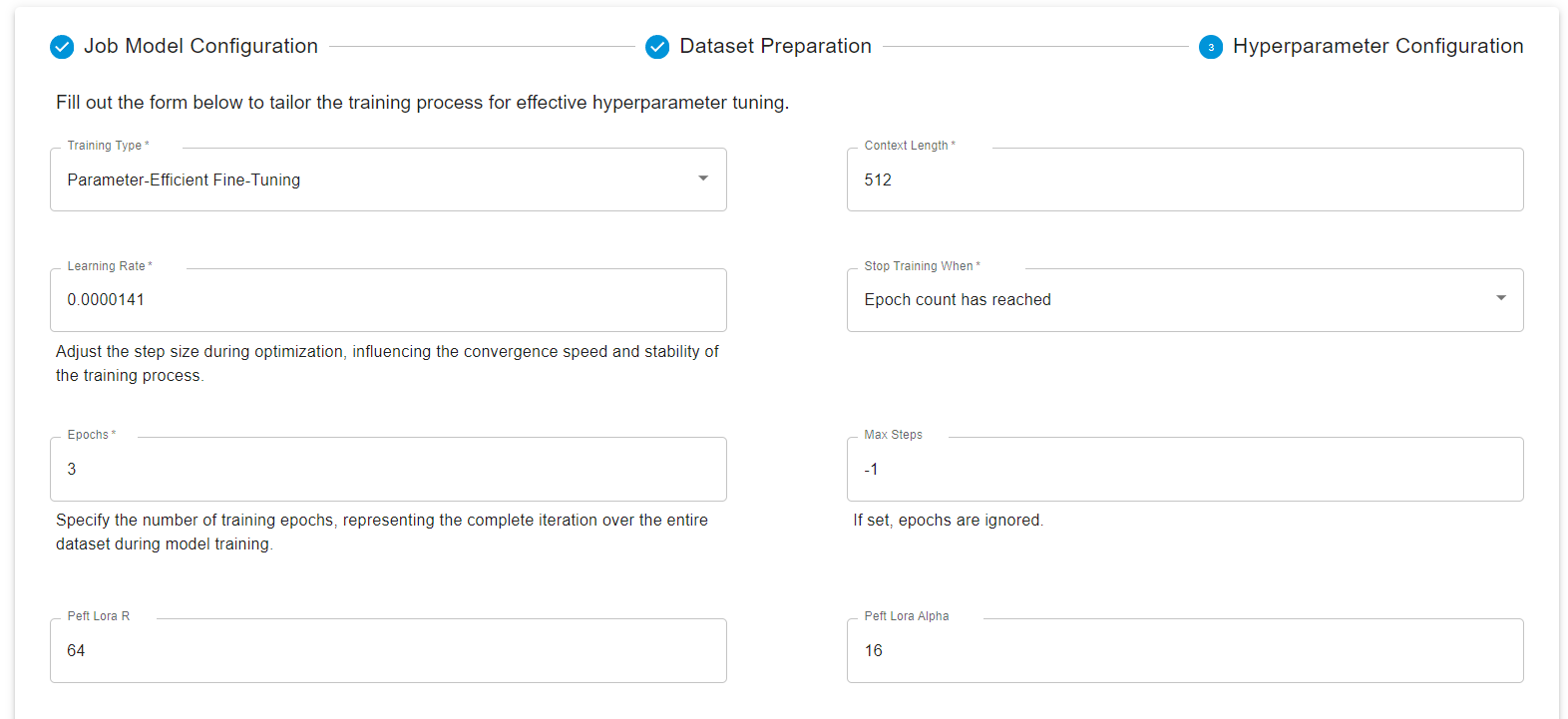
You can track the progress of the model with Wandb (Weights and Biases) if required. Select a GPU that’s best suited to your needs, and launch the fine-tuning job.

Post that, you will see your fine-tuned model in the list below:
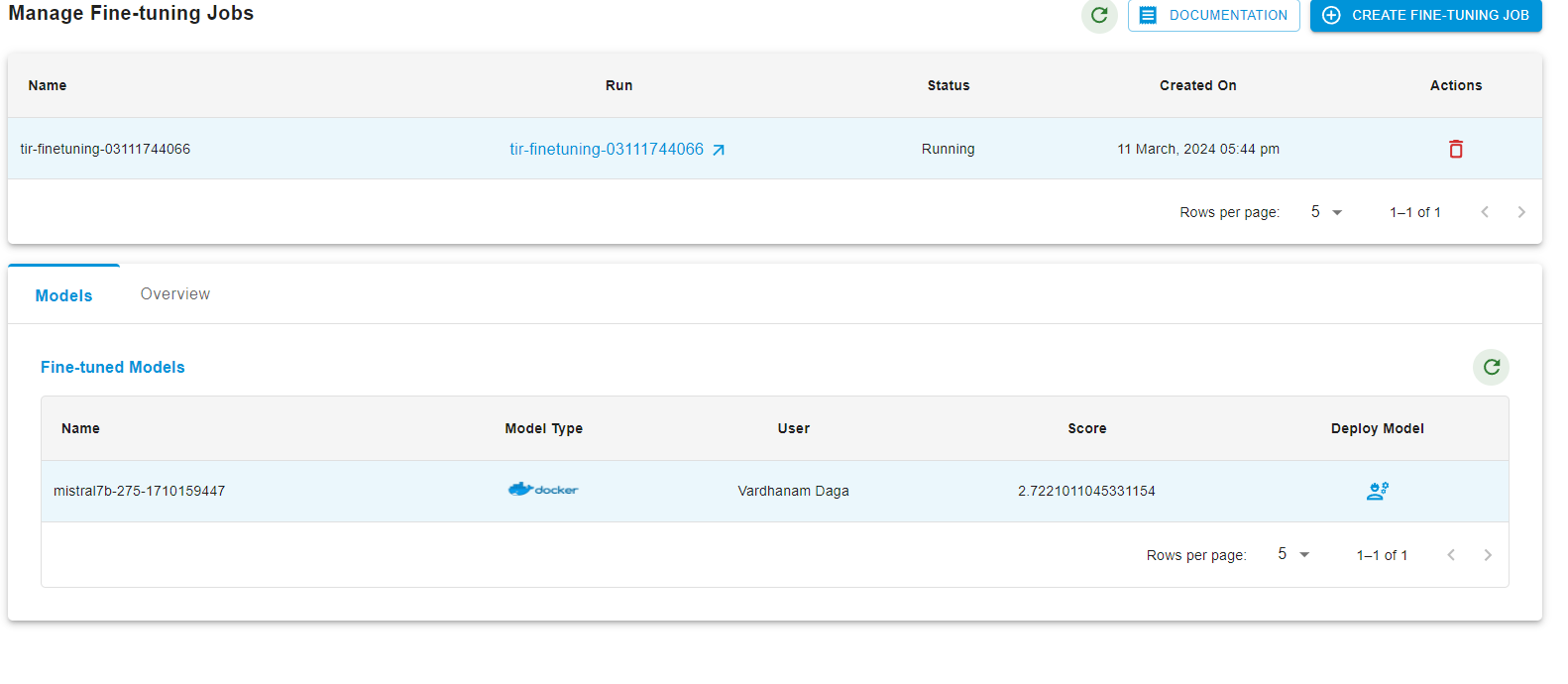
Your fine-tuned model is now ready for deployment.
Final Words
By following the steps provided, users can fine-tune models such as Mistral-7B using their own data or by accessing public datasets. The process involves converting datasets to the appropriate format, uploading them to the platform, configuring the fine-tuning process, and then monitoring the training job until completion.