Introduction
Large Language Models (LLMs) mark a significant evolution in the field of AI and NLP. Initially, language models were simple and small, but as the demand for more sophisticated and accurate natural language understanding (NLU) and natural language generation grew, so did the size and complexity of these models. This led to the emergence of models like ChatGPT, Llama, and BERT, which showcased an unprecedented ability to understand context, generate text, and even perform specific language tasks without extensive task-specific training. These models, characterized by their large number of parameters, have set new standards for what's possible in AI-driven communication, creativity, and comprehension.
While the large number of their parameters makes them performant, this aspect also places significant demands on computational resources. Training and running LLMs require lots of energy, time, and money, making them less accessible to the average researcher, developer, or small organization. Furthermore, as demand for LLMs grows across industries, so does the need for smaller domain-specific models.
Due to this, a new wave of small LLMs are arising, collectively known as mini-giants. These models are a response to the growing need for more accessible, efficient, and ethical AI tools. Mini-giants embody most of the key capabilities of their larger counterparts but are designed to be significantly smaller in size, requiring less computational power and resources to run. Despite their smaller size, these models are making impressive strides in performance, often rivaling or even surpassing larger models in specific tasks. This represents a paradigm shift in AI, prioritizing not just capability but also accessibility and efficiency. This can improve the reach of LLMs, making it a more integrated and practical part of everyday solutions across industries.
Why Build Smaller-Sized LLMs?
Small LLMs are rapidly gaining popularity within the open-source community, reflecting a broader trend towards more accessible and efficient AI tools. They address several critical challenges associated with large LLMs:
- Costs: Training and maintaining large-scale LLMs involve substantial investment, making them too resource-intensive for use in myriad use-cases where smaller models could suffice.
- Resources: The computational power required to train and run large models is immense. For complex and sophisticated AI applications, organizations commit to GPU setups like HGX 8xH100 or A100s. However, for simpler tasks, often less expensive GPUs such as L40S , A30, A40 suffice.
- Accessibility: Large models are less flexible and harder to adapt to specific needs or constraints. Smaller models, on the other hand, offer greater adaptability and are easier to fine-tune for specialized tasks or to fit within the constraints of specific hardware, making them suitable for a wide range of applications, from mobile devices to embedded systems.
The rise of mini-giants is a response to these challenges, representing a shift towards wider applications of AI. By reducing the barriers to entry and making powerful language models more widely available, mini-giants can become a catalyst for a more inclusive and responsible approach to AI.
Strategies for Downsizing LLMs
There are several strategies that have been developed to downsize LLM, while maintaining performance. These techniques vary in approach and impact.
- Model Pruning involves removing the least important weights or neurons from a model, reducing its size without significantly impacting performance. This technique improves the model, making it faster and less resource-intensive, although it requires careful implementation to ensure vital features aren't lost in the pruning process.
- Knowledge Distillation is a method where a smaller model learns to replicate the behavior of a larger model. By training the student model to mimic the outputs of the teacher, knowledge distillation captures the essence of the larger model's capabilities, resulting in a compact model with performance that can approach that of the original, depending on the intricacies of the relationship and training methods.
- Quantization decreases the precision of the model's parameters, converting them from floating-point representations to lower-bit formats. This reduction also accelerates inference times. The trade-off typically involves a minimal loss in accuracy, which can often be mitigated or calibrated for specific tasks.
- Parameter Sharing reduces the model's footprint by using the same parameters across multiple model components, reducing the total number of unique parameters without drastically sacrificing the model's expressive power. While it improves the model, it may also limit the model's flexibility in handling diverse or complex tasks.
Enhancing fine-tuning efficiency is also crucial. It makes the model more adaptable and easier to customize with less computational resources.
- Transfer Learning involves adapting a pre-trained model to new tasks by fine-tuning it on a smaller, task-specific dataset. This approach is resource-efficient and uses the model's pre-learned features, although its effectiveness depends on the relevance of the pre-trained model to the new task.
- Instruction Tuning involves training a small set of parameters or using prompts to guide the model's responses to specific tasks. This method allows rapid adaptation with minimal resource requirements but may vary in effectiveness based on how different the new tasks are from the original training.
- Adapters are small, task-specific modules inserted into a pre-trained model, allowing targeted adjustments without retraining the entire model. Adapters offer a balance between customization and efficiency, enabling more precise model tuning with less computational overhead.
Each of these strategies reflects a commitment to making language models more usable and effective across a broader range of scenarios. As the field continues to evolve, these techniques are refined and combined, driving towards an era of more sustainable, adaptable, and accessible AI.
Comparative Study of Small Language Models
When choosing small language models, it is crucial to consider various factors like parameter size, performance, innovation, and real-world applications. Let us look at some of the notable small LLMs that have made significant impacts in the field.
- DistilBERT from Hugging Face combines the essence of BERT's language understanding capabilities in a package that's 40% smaller. Despite its reduced size, DistilBERT retains 97% of BERT's performance, making it an efficient alternative for a variety of NLP tasks. Developed by Hugging Face, this model is a testament to the power of model distillation techniques and is widely used in scenarios where efficiency and speed are critical without substantially compromising the quality of results.
- GPT-Neo from EleutherAI is an open-source initiative aimed at democratizing access to powerful language models. Available in different sizes, with a popular variant around 2.7 billion parameters, GPT-Neo seeks to provide performance comparable to GPT-3. It's particularly notable for its commitment to open-source principles, allowing for broad adaptation and innovation across various applications from text generation to more sophisticated conversational agents.
- TinyBERT from Huawei is specifically designed for environments where efficiency is crucial, such as mobile or edge computing. Despite its significantly smaller size compared to the original BERT, TinyBERT uses competitive performance on language understanding benchmarks. The model focuses on transformer distillation techniques, offering a solution that balances the need for compact, efficient models with the desire for robust performance in language tasks.
MobileBERT is optimized for speed and size, specifically targeting mobile platforms. This model is a variant of BERT tailored for on-device performance, providing lower latency and enhanced privacy for users. MobileBERT's architecture can be viewed as making powerful NLP tools more accessible and practical for real-world mobile applications, enabling robust language understanding and generation tasks directly on users' devices.
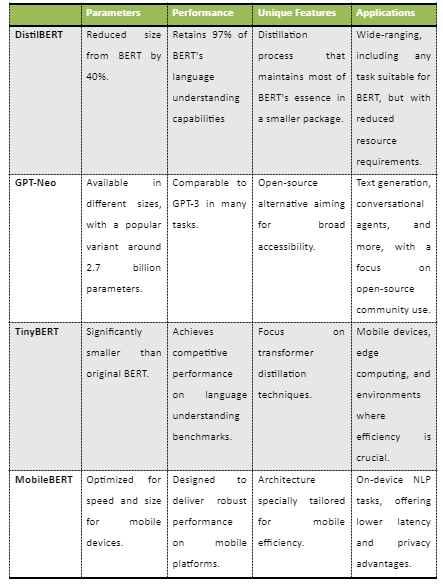
In summary, these small language models represent a significant shift towards making NLP more accessible and efficient. Each brings unique innovations and strengths to the table, from DistilBERT's efficient distillation approach to GPT-Neo's open-source accessibility, TinyBERT's focus on transformer techniques, and MobileBERT's mobile optimization. As the field evolves, these mini-giants continue to push the boundaries of what's possible, offering powerful capabilities for a wide range of applications while addressing the constraints of resource efficiency and accessibility.
Real-World Applications and Advantages
Small LLMs offer a lot of advantages that make them particularly suitable for a wide range of real-world applications. Two of the most significant advantages are their ability to protect user privacy and their computational efficiency.
- Privacy Protection: In a time period where data privacy is important, small LLMs offer a solution. They can be deployed locally on a user's device or within an organization's private infrastructure, significantly reducing the risk of sensitive data being exposed to third-party servers. This local deployment capability is especially crucial for industries handling sensitive information, such as healthcare, finance, and legal services. By keeping data on-premises, organizations can maintain control over their information and adhere to strict privacy regulations and standards.
- Computation Efficiency: Mini-giants are designed to be lean and efficient, requiring fewer computational resources than their larger counterparts. This efficiency leads to faster training and inference times, lower energy consumption, and reduced operational costs. The ability to run on less powerful hardware, including mobile devices and embedded systems, opens up new possibilities for integrating advanced language processing capabilities into a broader array of products and services.
Case Study of a Small LLM
A compelling case study of small LLMs is seen in the application of a hypothetical therapeutic chatbot. This chatbot integrates principles from Cognitive Behavioral Therapy (CBT) to provide timely mental health support and interventions. It's designed to engage users in meaningful conversation, offering guidance and support for mental wellness.
- Increased Privacy: Operating directly on a user's device, the chatbot ensures privacy and confidentiality, a must-have for users sharing sensitive personal information. This on-device deployment makes mental health support accessible anytime, overcoming barriers to traditional therapy such as availability, stigma, and cost.
- Efficiency in Interactions: The chatbot would respond promptly and contextually to user inputs. This immediate interaction in spite for light weight keeps users engaged and ensures that the therapeutic advice is consistent, personalized, and timely. The chatbot's ability to learn and adapt to individual user needs while maintaining a conversational flow is a direct benefit of the underlying small LLM's capabilities.
The prospective applications and advantages of mini-giants are vast and impactful. By prioritizing privacy and efficiency, these models are well-positioned to revolutionize how industries operate and how services are delivered, particularly in fields where privacy is critical. The hypothetical case study of a therapeutic chatbot is just one example of how small LLMs can be applied to address complex challenges in daily life. As small LLMs continue to evolve, their role in driving innovation and improving services is expected to expand, marking a significant shift towards more accessible, efficient, and responsible AI.
Technical Considerations
Integrating small LLMs into various domains, particularly sensitive ones like healthcare, presents a unique set of technical challenges. These challenges need to be carefully navigated to ensure the responsible and beneficial use of AI technologies.
- Integration with Existing Systems: In many industries, integrating new technologies with existing systems and workflows can be complex and resource-intensive. Small LLMs must be adaptable and compatible with different types of infrastructure and data formats, requiring robust and flexible design.
- Maintaining Accuracy: While smaller models offer efficiency, ensuring they maintain a high level of accuracy and reliability, especially in critical domains like healthcare, is essential. Continuous monitoring and validation are required to ensure that the models perform consistently and as expected.
- Handling Bias: Small LLMs must be capable of understanding and processing a wide variety of data types and languages. Additionally, they need to be trained and regularly updated to avoid biases and inaccuracies that could lead to harmful decisions, especially in sensitive applications
Ethical Considerations
Similarly, small LLMs also pose ethical challenges, which needs to be addressed. These considerations can be considered not only for small LLMs, but for LLMs in general.
- Data Protection: Ensuring user data privacy and protection is necessary, especially when dealing with sensitive personal information. Small LLMs need to be designed with privacy-preserving features, and their deployment must comply with data protection regulations such as GDPR, HIPAA, or others relevant to the specific industry and region.
- Transparency: There is a growing demand for AI systems to be transparent, especially when they're used in critical decision-making. Users should understand how the model makes decisions, what data it uses, and what limitations it might have. This is particularly important in healthcare, where understanding the rationale behind a diagnosis or treatment recommendation is crucial.
- Ethical Use: As small LLMs become more widely used, ensuring that they are deployed and used ethically is essential. This involves considering the potential impacts on academic cheating, employment, mental health, and societal norms. It also means avoiding the use of these models in applications that could lead to harm or discrimination.
- Regulatory Compliance: Each industry, especially healthcare, is governed by a set of regulations and standards that ensure safety and efficacy. Small LLMs must be developed and deployed in compliance with these standards, which might involve rigorous testing, certification, and ongoing oversight. Navigating the regulatory landscape can be complex, requiring a clear understanding of the requirements and processes involved.
Future Trends and Conclusion
The open-source community has been a significant beneficiary of a diverse ecosystem. Platforms like Hugging Face and initiatives like EleutherAI have created communities around sharing, improving, and deploying small LLM models. This collaborative environment accelerates the development of small LLMs and ensures that the knowledge and benefits are shared. The landscape of small LLMs is evolving rapidly, driven by a combination of technological advancements, growing demand, and a vibrant community of developers and users. As these models become more sophisticated and widespread, they will play an increasingly central role in shaping the future of AI, making it more accessible, efficient, and impactful. The journey of small LLMs is just beginning, and the potential for positive change and innovation is vast, promising a future where AI is not only powerful but also widely available and beneficial for everyone.
These models are set to transform industries by providing powerful tools that were once the domain of only the most resource-rich organizations. Now, they are within reach of a broader audience, from independent developers and startups to educational institutions and non-profits. The significance of mini-giants lies in their potential to democratize AI. By reducing the resource requirements traditionally associated with sophisticated AI applications, they open up opportunities for innovation and development to a much wider community.
Small LLMs are also transforming industries by enabling more efficient and effective solutions. In industries like healthcare, education, and customer service, it is possible to provide high-quality, AI-powered services and insights that are faster, more accurate, and more accessible. They can also be deployed in a variety of contexts, from mobile apps and embedded systems to large-scale enterprise solutions.
The journey of mini-giants is far from over, and ongoing innovation is crucial to realizing their full potential. As the technology continues to evolve, it is important for the developers, researchers, users, and policymakers to stay engaged, share knowledge, and collaborate on developing best practices and standards. This engagement includes not only technical development but also a commitment to ethical considerations. As the use of mini-giants expands, it is imperative to ensure that they are developed and deployed responsibly, with attention to issues like privacy, bias, and transparency. The community must work together to address these challenges, ensuring that AI serves the greater good.
Small LLMs are a beacon of innovation and democratization in the AI landscape. They embody the promise of AI that is accessible, powerful, and beneficial, marking a significant step towards a future where the advantages of AI are shared widely and responsibly. The continued evolution of these models will bring new challenges, but with ongoing innovation, community engagement, and a commitment to responsible development, the potential for positive impact is immense.









